この記事は Salesforce Platform Advent Calendar 2017 の 3 日目の記事です。
はじめに
アドベントカレンダーなので「私の Salesforce 情報収集術!(2017 年冬)」とかでお茶を濁そうと考えていたんですが
Winter'18 で Packaging 2.0 がベータ版となり、機能自体は誰でも試せるようになりました(リリースノート)。
というわけでやってみたレポです。
なお、最近 Salesforce DX 開発者ガイド が日本語版も公開されたため そこに書かれていることを一通りなぞっただけの記事になってしまいました。
開発者ガイドによると「第二世代パッケージ」と表現してるので、この記事でも以降そう呼びます。
事前準備
事前に必要な各種設定を行っていきます。
開発者ガイドで言うとここです。
組織の設定の確認 | Salesforce DX 開発者ガイド | Salesforce Developers
Salesforce DX CLI のインストール、Dev Hub 組織のサインアップ
第二世代パッケージは DX による開発を前提としています。
そのため、 sfdx コマンドおよび Dev Hub 組織を利用可能にしておく必要があります。
このあたりは Trailhead の App Development with Salesforce DX というモジュールに手順が書いてありますので割愛します。 または、先日そのハンズオン勉強会をやったときの日本語の資料が ここ にあるのでそちらを参照ください。
Dev Hub 組織で第二世代パッケージを有効化する
第二世代パッケージはベータ版機能のため、組織の設定で有効化する必要があります。
開発 > Dev Hub を開きます。
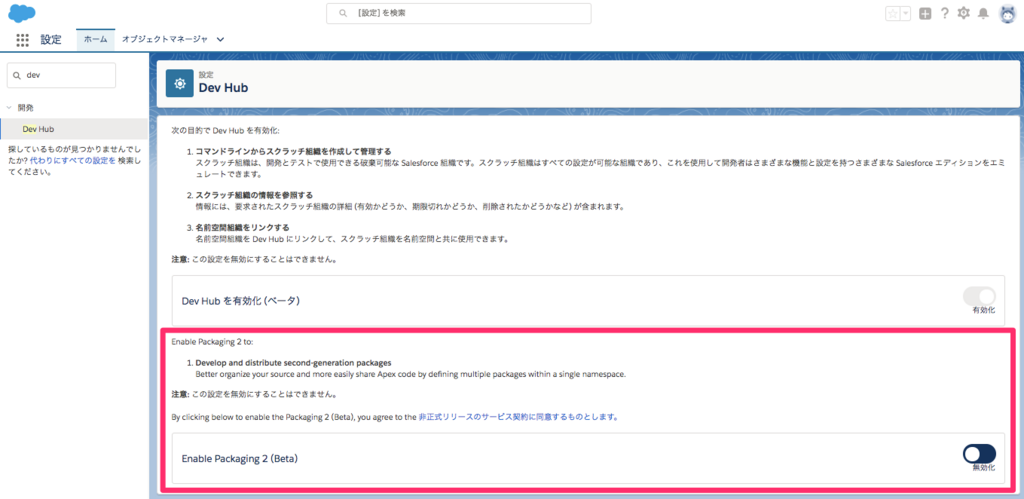
Dev Hub 組織の「私のドメイン」を有効化する
Dev Hub 組織の「私のドメイン」が有効でないと、この後の名前空間のリンクができないので有効にします。
30 日間のトライアル組織でも「私のドメイン」は有効になってないので忘れずにやります。
名前空間登録用の DE 組織をサインアップ
パッケージの名前空間を登録するために、なぜか専用の Developer Edition 組織が必要になります。 https://developer.salesforce.com/signup からサインアップします。
組織にログイン後、アプリケーション > パッケージマネージャ から登録できます。
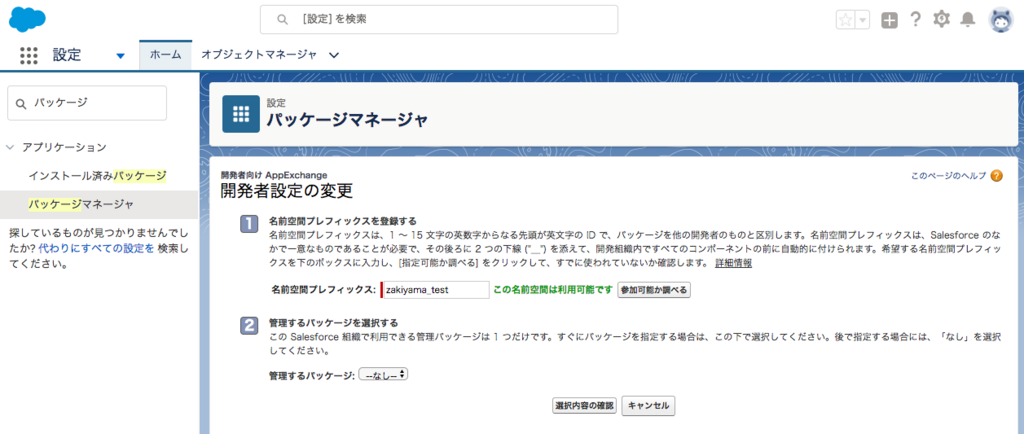
ちなみに、名前空間の登録も Dev Hub 組織使えばいいじゃんって思ったんですができないようです。

Dev Hub 組織で名前空間組織をリンクする
先ほど作成した名前空間組織を Dev Hub 組織にリンクします。
再度 Dev Hub 組織を開き、「Namespace Registry」タブを開きます。

「名前空間をリンク」ボタンを押すとポップアップが開くので、そこで名前空間組織にログインしアプリケーションを許可します。
(このボタン、「私のドメイン」が無効だと表示されません)
開発
準備が整ったので、プロジェクトを作ってパッケージ作成を試してみます。
DX 用新規プロジェクトを作成
CLI でプロジェクトのひな形を作ります。
$ sfdx force:project:create -n my-first-package-2 my-first-package-2 ├── README.md ├── config │ └── project-scratch-def.json ├── force-app │ └── main │ └── default │ └── aura └── sfdx-project.json
sfdx-project.json に名前空間を設定する
{
"packageDirectories": [
{
"path": "force-app",
"default": true
}
],
- "namespace": "",
+ "namespace": "zakiyama_test",
"sfdcLoginUrl": "https://login.salesforce.com",
"sourceApiVersion": "41.0"
}
Scratch Org で開発する
第二世代パッケージの作成とは直接関係ありませんが、通常はこの後 Scratch Org を作成して開発を行っていくことになります。
なお、Scratch Org を作成する際に名前空間が正しくリンクされていないと下記のエラーがでます。
$ sfdx force:org:create -f config/project-scratch-def.json -a ScratchOrg -s ERROR: 名前空間属性 foo に無効な値が指定されました。単純な Javascript 名にしてください。.
パッケージを作成する
開発が完了したという想定で、いよいよパッケージを作成します。
開発者ガイドではこのあたりです。
パッケージの作成 | Salesforce DX 開発者ガイド | Salesforce Developers
$ sfdx force:package2:create --name new_package --description "New Package" --containeroptions Unlocked Successfully created a second-generation package (package2). 0Ho7F0000008OIASA2 0337F000000HWJrQAO === Ids NAME VALUE ───────────────────── ────────────────── Package2 Id 0Ho7F0000008OIASA2 Subscriber Package Id 0337F000000HWJrQAO
成功すると Package2 Id と Subscriber Package Id という 2 つの ID 情報が表示されます。
Package2 Id はこの後すぐ使います。後者はなんだろう...
sfdx-project.json の packageDirectories にパッケージ ID などを追加する
ここが一番のハマりポイントでした。
sfdx-project.json ファイルでのパッケージの設定 | Salesforce DX 開発者ガイド | Salesforce Developers
によると
各パッケージの Salesforce DX プロジェクト設定ファイルにエントリを追加し、そのバージョンの詳細、連動関係、および組織設定を指定します。
各パッケージ説明には次の属性が含まれます。
{ "path": "logic", "id": "0HoB00000004CFuKAM", "versionName": "v 1.2", "versionDescription": "ver 1.2 - anc = 1.1", "versionNumber": "1.2.0.NEXT", "ancestorId": "05iB00000004CIeIAM", "dependencies": [ { "packageId": "0HoB00000004CFpKAM", "versionNumber": "1.2.0.LATEST" }, { "packageId": "0HoB00000004CFkKAM", "versionNumber": "1.2.0.LATEST" } ], "features": "MultiCurrency", "orgPreferences": { "enabled": [ "S1DesktopEnabled", "Translation" ], "disabled": [] } }
とありますが、これ実際には sfdx-project.json の packageDirectories プロパティの中に記述する必要がある みたいです。
(Dreamhouse アプリのリポジトリ 見てなんとかわかった...!)
{
"packageDirectories": [
{
"path": "force-app",
+ "id": "0Ho7F0000008OIASA2",
+ "versionNumber": "1.0.0.NEXT",
"default": true
}
],
"namespace": "zakiyama_test",
"sfdcLoginUrl": "https://login.salesforce.com",
"sourceApiVersion": "41.0"
}
この 2 つ以外にもバージョンや依存関係まわりのプロパティが多数あるようなんですが、今の時点では詳細はわかってません。
パッケージバージョンを作成する
作成したパッケージに対し、今度はバージョンを作成します。
パッケージを作成したときの Package2 Id を使って
$ sfdx force:package2:version:create -i 0Ho7F0000008OIASA2
とします。
成功すると
Package2 version creation request is InProgress. Run "sfdx force:package2:version:create:get -i 08c7F0000008OIKQA2" to query for status.
といったメッセージが表示されます。
(余談)
バージョン作成の部分、開発者ガイドでは
次のコマンドでパッケージバージョンを作成します。ディレクトリ名またはパッケージ ID を指定します。
と記載があり、 -d による対象ディレクトリ指定か -i による対象パッケージ Id 指定のいずれかでいけるようです。
が、どちらの場合も sfdx-project.json に id を指定しなくて良いわけではなく、以下のエラーが出ました。
ERROR: The --package2id (-i) value [0Ho7F0000008OIASA2], doesn’t match the id value in any packageDirectories specified in sfdx-project.json.
正しい設定方法は未だによくわかっていません。。。
バージョン作成の進行状況を確認する
GUI から作成したときと同じく、パッケージバージョンの作成は少し時間がかかるようです。
作成コマンド実行時に表示された以下のコマンドで、状況を確認することができます。
$ sfdx force:package2:version:create:get -i 08c7F0000008OIKQA2 === Package2 Version Create Request NAME VALUE ────────────────────────────── ────────────────── ID 08c7F0000008OIFQA2 Status InProgress Package2 Id 0Ho7F0000008OIASA2 Package2 Version Id Subscriber Package2 Version Id Tag Branch Created Date 2017-12-04 03:59
結果
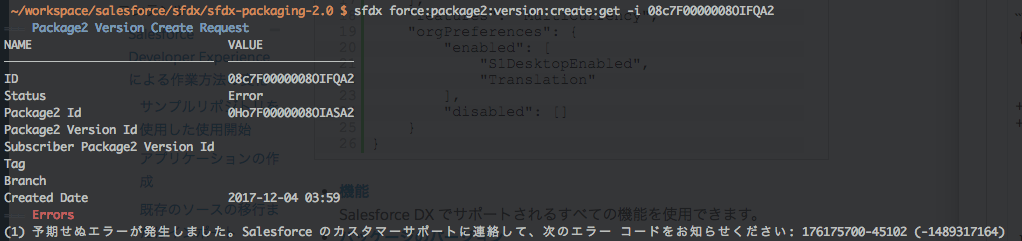

ウッ😇
今日はここまで。。。
おわりに:まだまだわからないことだらけ
というわけで、何とも消化不良な結果に終わってしまいました。。。
まあエラー自体はもう少し時間をかければなんとかなるんでしょうが。
今回やってみただけでは、以下のような点がいろいろとわかっておりません。
- バージョン作成時の正しい Package2 Id の指定のしかた
sfdx-project.jsonに埋め込んじゃうのが適切なの?
- バージョン指定用の各種プロパティ
- パッケージ作成時の
--containeroptionsの違い - 各種 ID
- https://developer.salesforce.com/docs/atlas.ja-jp.sfdx_dev.meta/sfdx_dev/sfdx_dev_dev2gp_plan_pkg_types_pkg_ids.htm
- パッケージ作成時に表示された
Subscriber Package Id以外に、要求 ID なども - 用語を整理したい