毎回忘れるのでメモ。 SUM でなく SUBTOTAL 関数を使う。
適用できる関数は色々あるが、 SUM の場合 9 を指定すれば OK。
=SUBTOTAL(9, A2:A50)
A2:A50 はフィルタしてる領域の全体行。
毎回忘れるのでメモ。 SUM でなく SUBTOTAL 関数を使う。
適用できる関数は色々あるが、 SUM の場合 9 を指定すれば OK。
=SUBTOTAL(9, A2:A50)
A2:A50 はフィルタしてる領域の全体行。
Passport.js を使ってみる回その4です。
以前の記事はこちら:
前回までで、認証したユーザー情報を MongoDB に保存することができました。
これで一件落着かと思われたのですが、よくよく考えるとこの後認証先のサービス(ここでは Google)の API を利用するとなると
アクセストークンが必要になります。これも保存しておかないといけませんね。
また、アクセストークンには有効期限が定められているものもあります。
その場合は「アクセストークンが期限切れになったら、リフレッシュトークンを使って新しいアクセストークンを取得し、再度 DB に保存する」という処理も入れなければいけません。
調べてみたところ Passport.js ではそのためのライブラリとして passport-oauth2-refresh というものがあるようです。
(あんまスターついてなくて心配。。。)
というわけで今回はまず、アクセストークンとリフレッシュトークンも DB に保存するようにした後、
passport-oauth2-refresh を使ったアクセストークンの更新処理も実装してみます。
PR は https://github.com/zaki-yama/passport-express-oauth2/pull/2
本旨とは関係ありませんが、先に今回用意した API のコードを載せておきます。
内部的に Google Tasks API を叩いて Tasklist を取得します。
// routes/api.js import express from 'express'; import fetch from 'node-fetch'; const router = express.Router(); router.get('/tasklists', (req, res) => { console.log('/tasklists', req.user); fetch(`https://www.googleapis.com/tasks/v1/users/@me/lists?access_token=${req.user.accessToken}`) .then((response) => { return response.json(); }) .then((data) => { console.log(data); return res.json(data.items); }); }); export default router;
アクセストークンが切れなければこのままでも問題ありませんが、時間が経つと Google Tasks API のレスポンスが 401 になってしまいます。
これは簡単です。
認証時に accessToken, refreshToken は取得できていたので、ユーザーモデルにこれらを追加して一緒に保存してしまいます。
// models/user.js
const userSchema = mongoose.Schema({
_id: String,
displayName: String,
+ accessToken: String,
+ refreshToken: String,
image: String,
});
// routes/auth.js - User.findByIdAndUpdate(profile.id, extractProfile(profile), { + const user = { + accessToken, + refreshToken, + ...extractProfile(profile), + }; + + User.findByIdAndUpdate(profile.id, user, {
$ yarn add passport-oauth2-refresh
でインストールします。
// routes/auth.js // [START setup] import passport from 'passport'; import passportGoogleOauth2 from 'passport-google-oauth20'; +import refresh from 'passport-oauth2-refresh'; import User from '../models/user'; ... // along with the user's profile. The function must invoke `cb` with a user // object, which will be set at `req.user` in route handlers after // authentication. -passport.use(new GoogleStrategy({ +const strategy = new GoogleStrategy({ clientID: process.env.CLIENT_ID, clientSecret: process.env.CLIENT_SECRET, // FIXME: Enable to switch local & production environment. ... console.log(err, user); return done(err, user); }); -})); +}); +passport.use(strategy); +refresh.use(strategy);
ここもそんなにやることはないですね。元々 passport.use() にストラテジーを渡していたのと同じことを refresh.use() に対してもやります。
最初に紹介した /routes/api.js にアクセストークンが有効期限切れだったときの処理を入れると、以下のようになります。
これは、 passport-oauth2-refresh の Issue に書かれていたコードを参考にしたものです。
Mongoose でのモデルの save 方法などは↑のコードとは違うようなので、そこは直してます。
import express from 'express'; import fetch from 'node-fetch'; +import refresh from 'passport-oauth2-refresh'; const router = express.Router(); router.get('/tasklists', (req, res) => { - console.log('/tasklists', req.user); - fetch(`https://www.googleapis.com/tasks/v1/users/@me/lists?access_token=${req.user.accessToken}`) - .then((response) => { - return response.json(); - }) - .then((data) => { - console.log(data); - return res.json(data.items); - }); + const user = req.user; + const makeRequest = () => { + console.log('/tasklists', user.accessToken); + fetch(`https://www.googleapis.com/tasks/v1/users/@me/lists?access_token=${user.accessToken}`) + .then((response) => { + if (response.status === 401) { + console.log('response status 401. Retry'); + // Access token expired (or is invalid). + // Try to fetch a new one. + refresh.requestNewAccessToken('google', user.refreshToken, (err, accessToken) => { + // TODO: Error handling + console.log('new access_token', accessToken); + + // Save the new accessToken + user.accessToken = accessToken; + user.save().then(() => { + makeRequest(); + }); + }); + } + + console.log(response.status); + return response.json(); + }) + .then((data) => { + console.log(data); + return res.json(data.items); + }); + }; + + return makeRequest(); }); export default router;
fetch を使った場合、ネットワークエラーでもない限りレスポンスは then() に渡されるので、 response.status の値で 401 が返ってきていないかチェックします。
401 で返ってきた場合はアクセストークン有効期限切れの可能性があるので、
refresh.requestNewAccessToken()
で新しいアクセストークンを取得します。
レスポンスの第二引数には新しいアクセストークンが渡されてくるので、あとはこのアクセストークンでユーザーモデルの内容を上書きして保存( user.save() => { ...)すればいいですね。
ただしリトライ数には上限がないので、Issue のサンプルコードと同じように
const retry = 2 などを用意するmakeRequest() 時にデクリメントするretry <= 0 の場合は 401 画面を出すとした方がいいと思います。
また、今回は簡単なサンプルコードのため API が一つしかなく、その中にアクセストークン更新処理&リトライを書いてますが、
これはおそらくすべての API で共通な処理となると思うので、独立した関数にする?など工夫が必要そうです。
エラーハンドリングを諸々省略してるので、もうちょっと安全にするためにはそういった処理も必要そうです。
なんか動作検証してたら UnhandledPromiseException がちょいちょい出てた気がする(けどリロードしたら出なくなる)んですが、 user.save() に失敗しているとかかな...
メモです。
承認プロセスの設定で、「割り当て先として使用するユーザ項目」というのが出てくるけどどういう挙動になるのかわからず。
合わせて、その下にある「XXX 所有者の承認者項目を使用」というチェックボックスについても。
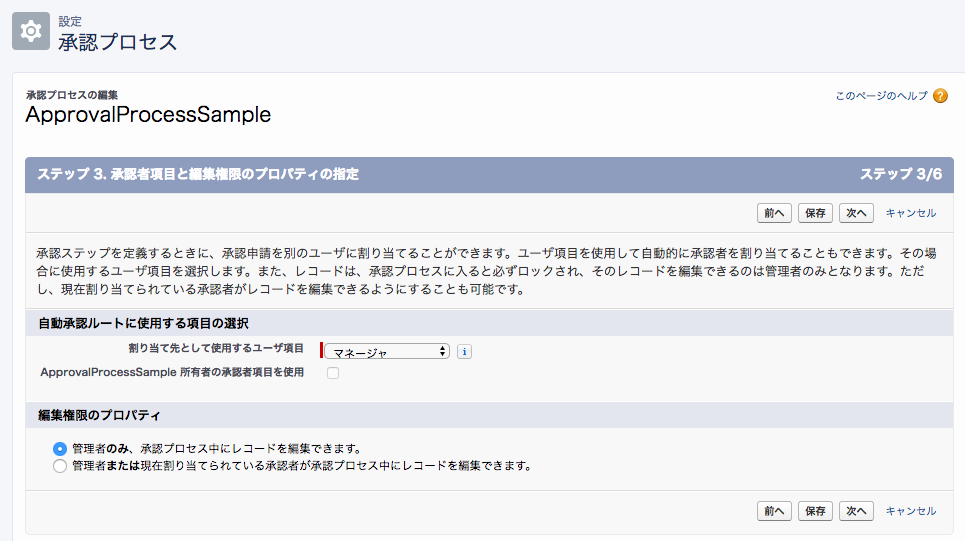
公式ドキュメントはこちら。
承認プロセスで自動化された承認者の選択
ユーザオブジェクトの任意の項目(※)を設定しておくと、続く承認ステップの設定で「ユーザのこの項目に設定した人を承認者にする」ということができるようになる。
※ただし階層関係の項目のみ。カスタム項目を作らない限り該当するのは「マネージャ」項目だけ
この項目を設定せずに承認ステップの割り当て先(承認者)の選択画面を開くと、選択肢として選べるのは以下のいずれか。
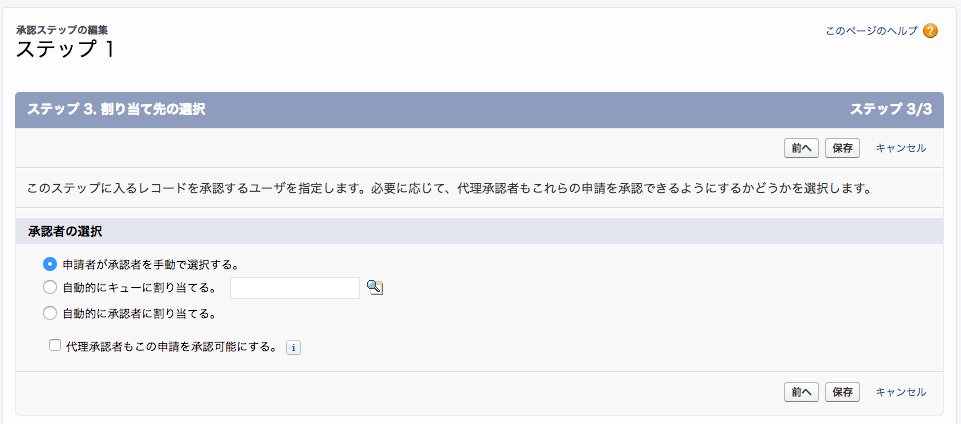
ここで、ユースケースとして「申請者のマネージャを承認者に設定したい」というのは割とありそうだが、上記の選択肢では実現できない。
このときに先ほどの項目を使う。
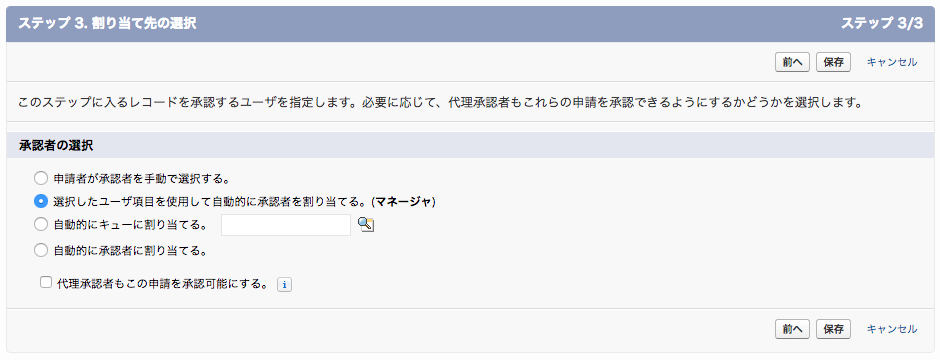
設定すると上のキャプチャのように、「選択したユーザ項目を使用して自動的に承認者を割り当てる。」という選択肢が1個増える。
このような設定にしておくと、申請時に申請者のマネージャ(人によって異なる)が自動的に承認者に選ばれるようになる。
デフォルトでは「マネージャ」しか選べないが、ユーザのカスタム項目で階層関係型の項目を追加してあげればそちらを利用することも可能。
こちらは、申請するレコードの所有者と申請者が異なる場合に承認者の選ばれ方が変わってくる。
ユーザの階層関係項目を使って承認者を選ぶところは同じだが、ON にすると文字通り、承認者はレコードの「申請者」ではなく「所有者」に設定されている内容を見に行く。
なのでたとえば、部長 > 上司 > 部下 という 3 人のユーザがいて、
という設定をしているとする。
この状態で「部下」が所有者になっているレコードを申請するとき、
という挙動になる。
第5章エンティティのメモが書けないまま第6章を終えてしまった。
ので、記憶の新しいうちに値オブジェクトの方のメモを書く。
-2^31 ~ 2^31 - 1 までの整数を許容してしまうが、数量にマイナスはない。また要件によっては最大値もあるかもしれないし、その場合バリデーションロジックを記述することで要件が明確になる可能な限り、エンティティよりは値オブジェクトを使ってモデリングすべきだと聞いたら、驚くかもしれない。ドメインの概念をエンティティとしてモデリングしなければいけないとしても、そのエンティティの設計は、子エンティティのコンテナではなく値のコンテナとして組み立てるよう心がけるべきだ。このアドバイスは、単なる気まぐれによるものではない。値型は何かを計測したり定量化したり説明したりするときに使うもので、作成やテストがしやすいし、使うのも最適化するのも保守するのも楽だ。
あるモデル要素について、その属性しか関心の対象とならないのであれば、その要素を値オブジェクトとして分類すること。値オブジェクトに、自分が伝える属性の意味を表現させ、関係した機能を与えること。値オブジェクトを不変なものとして扱うこと。同一性を与えず、エンティティを維持するために必要となる複雑な設計を避けること。[Evans](97ページ)
値オブジェクトのメソッドに副作用がないことを担保するために、
— Shingo Yamazaki (@zaki___yama) 2017年9月20日
・テストの最初に値オブジェクトのコピーを作る
・オリジナル=コピーを確認する
・オリジナルの値オブジェクトのメソッドを呼び出す
・オリジナル=コピーであることをもう一回確認する#iddd_teamspirit
public void testCostPercentageCalculation() throws Exception { BusinessPriority businessPriority = new BusinessPriority(new BusinessPriorityRatings(2, 4, 1, 1)); BusinessPriority businessPriorityCopy = new BusinessPriority(businessPriority); assertEquals(businessPriority, businessPriorityCopy); BusinessPriorityTotals totals = new BusinessPriorityTotals(53, 49, 53 + 49, 37, 33); float cost = businessPriority.costPercentage(totals); assertEquals("2.7", this.oneDecimal().format(cost)); assertEquals(businessPriorityCopy, businessPriority); }
ググっても出てこなかった。文字とおり自己+委譲なので処理を自分自身のクラスの別のメソッドに任せているから?
以下がストラテジパターンにあたるというのがよくわからなかった。
public float costPercentage(BusinessPriorityTotals aTotals) { return (float) 100 * this.ratings().cost() / aTotals.totalCost(); } public float priority(BusinessPriorityTotals aTotals) { float costAndRisk = this.costPercentage(aTotals) + this.riskPercentage(aTotals); return this.valuePercentage(aTotals) / costAndRisk; } public float riskPercentage(BusinessPriorityTotals aTotals) { return (float) 100 * this.ratings().risk() / aTotals.totalRisk(); } public float totalValue() { return this.ratings().benefit() + this.ratings().penalty(); } public float valuePercentage(BusinessPriorityTotals aTotals) { return (float) 100 * this.totalValue() / aTotals.totalValue(); } public BusinessPriorityRatings ratings() { return this.ratings; }
ストラテジパターンの説明 や同じ箇所で言及されてる PofEAA のセパレートインターフェース なんかを見る限り、共通のインターフェースを用意してストラテジごとの実装は各クラスに分けて切替可能にする、とかのようだ。
↑の例だと、今は costPercentage() の算出ロジックが1種類しかないから実装をべたっと書いてしまっているけど、別の算出方法が登場した際にはどっかにインターフェースだけ定義して実装とは分離することになるんだろうか。
第6章も骨太で 2 回に分けてなんとか読み終えた。
6.2 節の、コンテキストをまたいだ場合にエンティティではなく値オブジェクトとして定義することで責務を少なめに抑える、というのがまだぴんと来ていない。
また 6.6 節については Hibernate というツール(ORM)の具体的な使い方が中心で最後まで読みきらなかったけど、コードが多かったせいか Hibernate がどういうものであるかは感じ取ることができてよかった。
詳しく知りたくなったらこのあたり読めばいいんだろうか。
Hibernateで理解するO/Rマッピング(1):O/Rマッピングの役割とメリット - @IT
10/4(水) 19:00 予定です。connpass ページ作ったら貼る。
行ってきました。
絶対ブログ書く人類枠だったのでブログ書きます。
ハッシュタグは #frontrend。また動画が FRESH! で観られます。
https://freshlive.tv/tech-conference/151511
FRESH! 鈴木雅佳 ( @sutiwo_ ) さん
service-worker/ - assets.js // Web フォント・CSS・JS ファイルのホワイトリストを作成 - index.js // イベントハンドラの登録 - register.js // SW がインストールされているかの確認
最終的に browserify で service-worker.js へ
DISABLED_SW_CACHE: boolブックテーブル 小林正弘( @masahiro_koba ) さん
※資料公開されたら貼る
#! (ハッシュバン)から / (パスルーティング)へアメーバブログ 侯斌 ( @houbin217jz ) さん
const loadExample = () => import('./ExampleComponent')ちゃんと追いつけてないんだけど、JSコードの細かい粒度に分割しすぎてファイル数増えて初回表示遅くなる、みたいなことはないんだろうか #frontrend
— Shingo Yamazaki (@zaki___yama) September 8, 2017
なるほど、SSRなら最初に表示する画面に必要なJSファイルはどんなに細かく分割されてても問題にならないんですね。気づけてませんでした、ありがとうございます!
— Shingo Yamazaki (@zaki___yama) September 8, 2017
HTTP/2 にしてないと細かく分割した JS はブラウザの同時接続数の問題になりそう...という予想は当たっていたが
SSR だと少なくとも(一番読み込みファイル数が多くなるであろう)初回表示でそういったことは問題にならないのか。なるほど。
話に出てきてあまり理解できなかったところの補足。私的メモに近い。
Service Worker というか PWA については Google for Mobile Workshop Day でやった Google のコードラボがわかりやすかった気がする。
で、やってみるとわかるが、Service Worker を使うためにブラウザが対応しているかチェックしたり起動ほか Service Worker のライフサイクルメソッドを手で実装するのはめんどくさいので
そのあたりよしなにやってくれるライブラリを利用する。
コードラボで紹介されていたのは sw-precache というライブラリだったが、最後の発表で紹介されてた workbox もおそらく似たようなことができるんだろう。
(どちらも触ってはいない)
また、Service Worker 自体はプッシュ通知など様々なことが行えるんだけど、とりあえず導入してその恩恵を受けるのにまずは静的アセットのプリキャッシュを試してみるといいですよ〜というのはコードラボでも Google の人が話してた気がする。
Intersection Observer については前々から聞いてはいたもののどういったものなのか知らなかったが、jxck さんの記事が参考になった。
Intersection Observer を用いた要素出現検出の最適化 | blog.jxck.io
また、lazy load については以前弊社の勉強会で外部の方がこういう LT をしてくれたんだが
そのときは難しくてわからなかった。。。今見たら多少は理解できるだろうか。
みんなにやさしいlazy loadと Reactそしてredux-observable - Google スライド
会の終わりに
「パフォーマンス測定のためのツールや見るべき指標などは、サイバーエージェント内で全体的に統一されているんですか?」
という質問をした。
(すいません、懇親会出られなかったので最後の発表内容とあまり関係ない質問をしてしまいました。。。)
で、
パフォーマンスのことは @1000ch に聞こう #frontrend
— ますぴー (@masuP9) 2017年9月8日
ということだったので帰り際 @1000ch さんにちょっとだけお話を伺うことができたんだけど、発表にも出てきた通り
を多くのプロダクトでは使用しているとのこと。
SpeedCurve というサービスは使ったことがなかったんだけど、特定の URL のページ表示速度を継続的に測定してくれるサービスみたい。
ただしこれはサーバーの場所やネットワーク速度などが固定された場所からの定期アクセスであり、実際のユーザーの環境ではない。
なので実際のユーザーがアクセスした時のパフォーマンスがどうだったのかは、測定結果を Google Analytics に送ることで収集しているらしい。
また Speed Index という指標についてはこのあたりを読むと勉強になった。
SSR + SPA、Service Worker、HTTP/2 などなど次々に実プロダクトに投入していて、そのあたりはさすがサイバーエージェントさんだなあというのが率直な感想です。
私は業務では Salesforce というプラットフォーム上でアプリ開発をしているので
正直 SSR とか Service Worker とかを業務で使うことはなさそうなんだけど、フロントエンドに関わる人間として知っておかないといけない技術だと思うし
今回 3 名とも事例という形でリアルな話を聞けたのは非常に有意義でした。
(正直めちゃめちゃ難しかったんですが)
また、個人的には最後の発表にあった、JS のコード分割を Atomic Design の Organisms 単位にしているという話が興味深かったです。
Atomic Design の考え方をそこに利用できるのねーという素朴な感想と、Atomic Design も導入して全てうまくいくようなものではなくて何が Atoms/Molecules/Organisms なのかはチームで共通認識を作る必要があると思っているんだけども、
その共通認識の形成や言語化をめんどくさがらずにちゃんとやっておくと今回のような一見関係ない話題でもメンバー同士の会話がしやすいんだろうなあと。
あとこれ。
パフォーマンス改善したこともだけど、継続的にきちんと測定できていることが素晴らしい #frontrend
— Shingo Yamazaki (@zaki___yama) 2017年9月8日
発表の中で、パフォーマンスと事業 KPI とを関連づけるという話がありましたが、それについてはこういった記事があるようです。
WebパフォーマンスとプロダクトKPIの相関を可視化する話
また、ちょうど今日(9/11)HTML5 Experts.js からタイムリーな記事が。読まねば。
「最近のWebパフォーマンス改善について知っておきたいコト」についてあほむに聞いてきた | HTML5Experts.jp
過去メモ
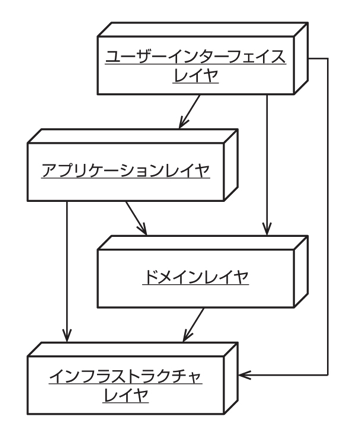
アプリケーションを関心ごとにいくつかの層に分割したアーキテクチャ。
Robert C. Martin が提唱した原則。
上位のモジュールは下位のモジュールに依存してはならない。どちらのモジュールも、抽象に依存すべきである。抽象は、実装の詳細に依存すべきではない。実装の詳細が、抽象に依存すべきである。
下位レベルのサービスを提供するコンポーネント(インフラストラクチャ)は、上位レベルのコンポーネント(UI やアプリケーション、ドメイン)が定義するインターフェースに依存すべきという考え。
以下の記事やスライドがわかりやすかった。
(スライドは依存性の注入(DI)まで言及してる)
たとえばドメイン層とインフラストラクチャ層の間で考えたとき、
と、利用するデータベースを変更することになってインフラストラクチャ層を別のクラスに置き換えようとしたときに、実装しているメソッドの名前や引数の型・数が異なると上位レイヤであるドメイン層にまで改修が必要になる。
これを、あらかじめインフラストラクチャ層のインターフェースを定め、
としておくと、下位レイヤのクラスは上位レイヤから見ていつでも交換可能となり、実装に依存しなくなる。
また上位レイヤも下位レイヤもインターフェース(抽象)に依存した状態となっている。
レイヤアーキテクチャではドメインに対して上位・下位という非対称な構成だったが、
「アプリケーション(ドメイン)層を中心に捉え、ユーザー操作/自動テストといった入力側もデータベース/モックといった出力側も、全てまとめて差し替え可能な外部インターフェイスとして扱う」という考え方
(http://codezine.jp/article/detail/9922?p=2 より引用)
をヘキサゴナルアーキテクチャと言う。
システムを、外部 と 内部 の二つの領域に分ける考え方だ。外部が、さまざまなクライアントからの入力を受け付ける。また、永続化されたデータを取得する仕組みを提供したり、アプリケーションの出力をデータベースなどに格納したり、メッセージングなどのその他の方法で出力を送信したりする。
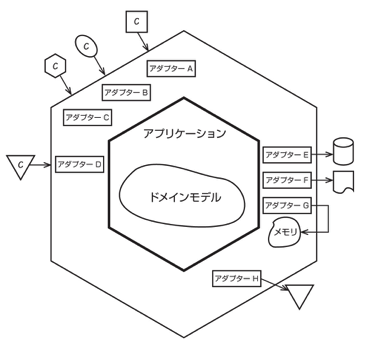
たとえば入力側としては、ブラウザからの入力や REST API でのアクセスといった異なる入力も、それぞれ専用のアダプターを用意することでアプリケーション(ドメイン)を同じように扱うことができる。
また出力側は、永続化機能として種々のデータベースに対応したアダプターを用意したり、あるいはテスト用のモックを扱うアダプターを用意することもできる。
ポートとアダプタの役割の違いや、どちらがより外側に位置するという扱いなのかはよくわからなかった。
データの「参照(クエリ)」と「更新(コマンド)」を分解するアーキテクチャパターン。
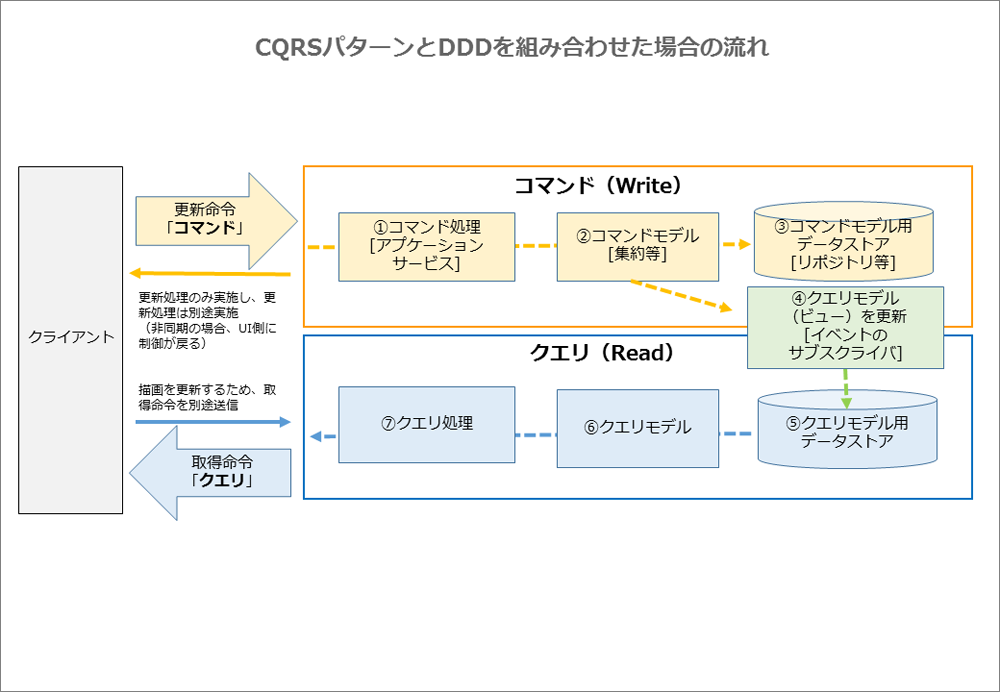
CQRS についてはこの記事が非常にわかりやすかった。
CQRSとイベントソーシングの使用法、または「CRUDに何か問題でも?」 | プログラミング | POSTD
図を見てもわかるように、クエリモデル用とコマンドモデル用で別々のデータストアを用意することもできる。
参照の際は、ユーザーのロール(一般ユーザー、マネージャー、管理者)に合わせて必要な別々のクエリモデルを用意しておくことができる。
表示したい内容の変更にはビューの変更だけで済む。
(現実的には RDBMS の場合、それぞれをビューとして定義しておく?)
更新の際は、「ユーザー情報を更新する」ではなく「メールアドレスを更新する」「請求先情報を変更する」というように目的に合わせたコマンドを用意することで、パーミッションチェックは特定のコマンドが実行可能かどうかだけをチェックすればよく、エンティティのどのフィールドが更新可能なのかという混乱がなくなる?
CQRSを深く考えずに実装するなら、単純にcreate、update、deleteのコマンドを用意すればよさそうです。しかしこれは、大事なことを見落としています。読み込みに使うデータモデルとコマンドを「別のもの」として明示的に切り離すということは、データを問い合わせる際に使うUserモデルとコマンドを実行するときに使うモデルとが違っていてもかまわないということです。ユーザー情報を更新するというのではなく、「メールアドレスを変更する」「請求先情報を変更する」なとどいうコマンドを考えることができるのです。CQRSなら、エンティティのどのフィールドが更新可能なのかといった混乱はなくなります。コマンドには、そのコマンドに関連するフィールドだけを含めることになるからです。パーミッションの考えかたも簡単になります。呼び出し元が変更しようとしているエンティティのフィールドが本当に変更してよいかどうかをチェックするのではなく、呼び出し元に特定のコマンドを実行する権限があるかどうかだけをチェックすればいいのです。
(http://postd.cc/using-cqrs-with-event-sourcing/ より引用)
イベントを待機し、起こったイベントに応じて処理を行うプログラムスタイル。
起こったすべてのイベントを順にデータベースに保存する。銀行の取引処理なんかがそう。
ある時点から発生したイベントを順に再生することで状態がいつでも復元できるため、監査やバグ調査において有効。
また先程の CQRS と相性がよい。CQRS の記事でも言及されているので参考になる。
第4章は紹介されている1個1個のアーキテクチャがかなり骨太な感じで、かつ DDD との関連もあまりよくわからないままざっと紹介だけされた印象を受けた。
第5章「エンティティ」も実は先日終わっているんだけど、早いとこ復習したい。
ちなみに次回は今週水曜日です。
Passport.js を使ってみる回その3です。
以前の記事はこちら:
前回は express-session を使い、認証したユーザーの情報をセッションに保存するところまでやりました。
そのときの TODO として、セッションの保存先がデフォルトではサーバー側のメモリ(MemoryStore)になっていたのですが、これは production 環境では推奨されないようです(参考(Warning のところ))。
そこで今回はセッションの保存先として MongoDB を使うように設定します。
詳しくは
dackdive.hateblo.jp
を見ていただきたいのですが、Mac の場合 Homebrew からインストールできます。
$ brew install mongodb # 以後、PC の起動時にプロセスを自動起動 $ brew services start mongodb # 起動確認 $ mongo MongoDB shell version v3.4.7 connecting to: mongodb://127.0.0.1:27017 MongoDB server version: 3.4.7 ... >
MongoDB を Node.js および Express で使うために必要なライブラリをインストールします。
Node.js から MongoDB を扱うためのライブラリには node-mongodb-native という MongoDB 公式のドライバもありますが、今回は mongoose というライブラリを使います。
mongoose は「object data modeling(ODM)tool」あるいは「O/R マッパーのように使えるライブラリ」などと説明されています。
$ yarn add mongoose
こちらは Express のセッションストアとして MongoDB を使うために必要なライブラリです。
express-session の compatible session stores にも記載されています。
$ yarn add connect-mongo
はじめに、データベースに保存する User データのモデルを定義します。
// models/user.js import mongoose from 'mongoose'; const userSchema = mongoose.Schema({ _id: String, displayName: String, image: String, }); export default mongoose.model('User', userSchema);
mongoose.Schema() に渡すオブジェクトでデータの型を定義します。
今回、データを一意に識別するための id には Google のユーザー Id を使用するため、 _id: String を指定します。
(何も指定しないと MongoDB の ObjectId 型になるみたいです)
mongoose.model() の第一引数はコレクション名を決めるもので、今回のように User とした場合、コレクション名は自動的に先頭小文字+複数形の users になります。
The first argument is the singular name of the collection your model is for. Mongoose automatically looks for the plural version of your model name. Thus, for the example above, the model Tank is for the tanks collection in the database.
サーバー側のエントリーポイントである app.js に、以下のように追記します。
import express from 'express'; import session from 'express-session'; +import mongoose from 'mongoose'; +import connectMongo from 'connect-mongo'; import path from 'path'; import passport from 'passport'; (略) + +const DATABASE_URI = + process.env.MONGOLAB_URI || + process.env.MONGOHQ_URL || + 'mongodb://localhost/myapp'; + +mongoose.connect(DATABASE_URI, { + useMongoClient: true, +}); +const MongoStore = connectMongo(session); app.use(session({ secret: 'keyboard cat', resave: false, saveUninitialized: true, + store: new MongoStore({ mongooseConnection: mongoose.connection }), cookie: { maxAge: 1000 * 60 * 60 * 24 * 30, }, }));
前半では mongoose.connect() メソッドを使い MongoDB へ接続します。
DATABASE_URI に環境変数を使っているのは、将来的に Heroku などの PaaS でも動かすことを想定しています。
Heroku の公式ドキュメント を参考にしています。
localhost/myapp の myapp の部分は任意の文字列で、これが DB 名になります。
また、 useMongoClient: true というオプションについては
http://mongoosejs.com/docs/connections.html#use-mongo-client
理由はちゃんと理解していませんが、バージョン 4.11.0 以降はこれを指定しないと起動時に warning が出るようです。
(node:47913) DeprecationWarning: `open()` is deprecated in mongoose >= 4.11.0, use `openUri()` instead, or set the `useMongoClient` option if using `connect()` or `createConnection()`. See http://mongoosejs.com/docs/connections.html#use-mongo-client
後半では express-session 用に MongoStore を作成し、 store オプションに指定することでセッションの保存先を MongoDB に変更しています。
なお、mongoose のセットアップを行った際のコネクションを再利用するため、 mongooseConnection オプションを指定しています。
これは connect-mongo の README に記載がありました。
https://github.com/jdesboeufs/connect-mongo#re-use-a-mongoose-connection
routes/auth.js を以下のように更新します。
passport.use(new GoogleStrategy({
clientID: process.env.CLIENT_ID,
clientSecret: process.env.CLIENT_SECRET,
// FIXME: Enable to switch local & production environment.
callbackURL: 'http://localhost:8080/auth/google/callback',
accessType: 'offline',
-}, (accessToken, refreshToken, profile, cb) => {
+}, (accessToken, refreshToken, profile, done) => {
// Extract the minimal profile information we need from the profile object
// provided by Google
- cb(null, extractProfile(profile));
+ User.findByIdAndUpdate(profile.id, extractProfile(profile), {
+ upsert: true,
+ new: true,
+ }, (err, user) => {
+ console.log(err, user);
+ return done(err, user);
+ });
}));
ここでは mongoose の findByIdAndUpdate() メソッドを使っています。
upsert: true を指定すると、文字通り DB にデータが存在しなかったときに insert してくれます。
また new: true を指定していますが、これは true の場合更新後のオブジェクトを、false の場合更新前のオブジェクトを返すようにするというオプションです。
最後に、routes/auth.js の serializeUser()、deserializeUser() メソッドを以下のように更新します。
passport.serializeUser((user, done) => {
console.log('serializeUser', user);
- done(null, user);
+ done(null, user.id);
});
-passport.deserializeUser((obj, done) => {
- console.log('deserializeUser', obj);
- done(null, obj);
+passport.deserializeUser((id, done) => {
+ console.log('deserializeUser', id);
+ User.findById(id, (err, user) => {
+ if (err || !user) {
+ console.log('Cannot find user', id);
+ return done(err);
+ }
+ console.log('Found user', user);
+ done(null, user);
+ });
});
今までは User 情報を丸ごとセッションに保存していたのですが、Id だけを保存するように serializeUser() を修正しました。
そうすると deserializeUser() 側の引数も Id になるので、今度はこの Id を使って users コレクションから User オブジェクトを検索します。
これはおまけですが、 / にアクセスしたときに req.user が存在するかどうか、つまり認証済みかどうかをチェックし
認証が済んでいない場合は Google の認証画面にリダイレクトするようにしておきます。
app.get('/', (req, res) => {
- console.log('user', req.user);
+ console.log('/', req.user);
+ if (!req.user) {
+ return res.redirect('/auth/login');
+ }
res.sendFile(path.join(__dirname, 'public', 'index.html'));
});
http://localhost:8080 にアクセスすると Google の認証画面にリダイレクトされ、許可するとトップに戻ってきます。
このとき、MongoDB の中身はどうなっているかというと
$ mongo MongoDB shell version v3.4.7 connecting to: mongodb://127.0.0.1:27017 MongoDB server version: 3.4.7 Server has startup warnings: 2017-08-27T16:16:32.068+0900 I CONTROL [initandlisten] 2017-08-27T16:16:32.068+0900 I CONTROL [initandlisten] ** WARNING: Access control is not enabled for the database. 2017-08-27T16:16:32.068+0900 I CONTROL [initandlisten] ** Read and write access to data and configuration is unrestricted. 2017-08-27T16:16:32.068+0900 I CONTROL [initandlisten] > show dbs admin 0.000GB local 0.000GB myapp 0.000GB > use myapp # myapp に切り替え switched to db myapp # sessions と users コレクションが作成されている > show collections sessions users # セッションの中身 > db.sessions.find() { "_id" : "kdBCv3ceCC_ufClCCuekOoeHtU-X_vMV", "session" : "{\"cookie\":{\"originalMaxAge\":2592000000,\"expires\":\"2017-10-02T02:50:00.016Z\",\"httpOnly\":true,\"path\":\"/\"},\"passport\":{\"user\":\"112492058384636445846\"}}", "expires" : ISODate("2017-10-02T02:50:00.038Z") } # ユーザー情報 > db.users.find() { "_id" : "112492058384636445846", "__v" : 0, "displayName" : "Shingo Yamazaki", "image" : "https://lh6.googleusercontent.com/-jwkJLbJL4wE/AAAAAAAAAAI/AAAAAAAACI/1MbHlZlCL5w/photo.jpg?sz=50" } >
というわけで、無事に保存されました。
認証済みのユーザー情報をデータベースに保存するため、MongoDB および mongoose を導入しました。
エラーハンドリングなど詰めが甘いところは多々ありますが、基本的な認証のしくみとしては整ったかと思います。
この後実際に Google の API を利用しようとすると、アクセストークンやリフレッシュトークンを使う必要があります。
そのため、おそらくこれらもユーザー情報にひもづけて保存しておく必要がありますね。。。
と、ここまでやってみて気づいたんですが、 Google の API を利用するのであれば専用の Node.js Client がライブラリとして提供されていました。
最初からこっちを使っていればよかったかも。。。
まあ、 Google 以外のサービスでも使える Passport.js の基本的な使い方がわかったから良しとするか。
(追記)
続編書きました。
(追記ここまで)
期限切れになったセッションの削除方法。
セッションの有効期限が切れると再度認証画面にとばされますが、そこで認証を行って戻ってくると sessions コレクションに新しいセッション情報がセットされます。
古くなったセッションは削除してもよさそうですが、方法がわからず。。。
")