読んだのでメモ。
本書の目次
PART I ドキュメント作成の準備
- CHAPTER 1 読み手の理解
- CHAPTER 2 ドキュメントの計画
PART II ドキュメントの作成
- CHAPTER 3 ドキュメントのドラフト
- CHAPTER 4 ドキュメントの編集
- CHAPTER 5 サンプルコードの組み込み
- CHAPTER 6 ビジュアルコンテンツの追加
PART III ドキュメントの公開と運用
- CHAPTER 7 ドキュメントの公開
- CHAPTER 8 フィードバックの収集と組み込み
- CHAPTER 9 ドキュメントの品質測定
- CHAPTER 10 ドキュメントの構成
- CHAPTER 11 ドキュメントの保守と非推奨化
この本について
ドキュメントを書くことになったエンジニアが意識すべきことが網羅的にまとめられた本、という印象。
本書の主張を端的に表すと「ドキュメントもプロダクト開発と同じような考え方で計画・実装・運用しましょう 」ということに尽きる、と解釈した。
プロダクト開発と同じように、とはたとえば次のようなこと。
読み手(ユーザー)を理解し、何がドキュメントとして必要なのかを書き始める前に明らかにしておこう
プロダクト開発において、機能を作る前にユーザーのニーズを把握しようという話と似ている
いきなり最終的な文章を書き始めるのではなく、はじめにアウトラインを作り、ドラフトを書こう
プロダクト開発において、実装前におおまかな設計方針を立ててレビューしたり、実装時にまずコメントでおおまかな処理を書いてから肉付けしていくやり方に似ている
レビュー時にはレビュー観点を明確にしよう
リリースプロセスを明確にしよう。最終レビュー者は誰か?どこに公開するのか?新しいコンテンツをどのように発表するか?
リリースしたドキュメントに対してユーザーからフィードバックを受けるチャンネルを作ろう
リリースしたドキュメントが良いものであったか、品質を測定しよう
なので、(これは読む前の期待値とギャップがあった箇所でもあるが)単に良い文章を書くためのポイントではなく、その前後も含めた計画フェーズ、運用保守フェーズについても書かれている。というよりそちらのほうに重点が置かれている。
そのため、きれいな日本語文章を書くためのテクニックが知りたいという人にはあまり適さないように感じた。そういう人には日本語スタイルガイドのような書籍のほうが適切だと思う。(そっちも買ったけど読み途中)
もうひとつ、読む前の期待値とのズレがあったところとしては、本書では主に開発者向けのドキュメントの書き方を扱っているというところ。そのため、たとえばCHAPTER5では1章まるまる使ってドキュメント中のサンプルコードについて言及されている。なので自分のように非開発者向けのドキュメントを書こうとしている人には少々学びにしにくいところがあるかもしれないが、CHAPTER5 以外はおおむねどんなドキュメントに対しても言えることが書かれていたように思う。
感想
ドキュメントを書く「前」と書いた「後」のことまで扱った書籍は初めて読んだので参考になった。特に、公開後の品質測定と保守、非推奨化のところは読んでいてなるほどと思う部分が多かった。
あと、末尾に発展的な学習のためのリソースや参考文献のリンクが大量にあってありがたい。
不満な点、というかいまいち腹落ちしきれなかった点があるとすると、本書はドキュメントを書く前から書いた後までを体系的に学べる分、一個一個のトピックについてはさらっとしている。そのため、具体的なテクニックについてはそこまで書かれておらず、明日からすぐに使える実用的な知識が身についたかと言われるとそうではなかった。
メモ
印象に残った箇所をメモ。
読み手(ユーザー)を理解する
CHAPTER 1 読み手の理解 より。
ユーザーのゴールを理解する
ユーザーがドキュメントを読んで達成したいこと(例:犬の鳴き声を人の言葉に翻訳する)と、ユーザー全体に渡る組織のゴール(例:Corg.lyのAPI を新規ユーザーが組み込めるように支援することで、新規ユーザーを獲得してオンボード する)との整合を取る
ユーザーを理解する
ユーザーが開発者だったら、スキルレベルは?役割は?
ユーザーの理解を検証する
サポートチケットなど既存の情報リソースを活用したり、インタビュー、開発者アンケートなどを通じて新しい情報を集める
ユーザー調査から得られた知見をまとめる
ペルソナ、ユーザーストーリー、ジャーニーマップ、フリクション ログ
個人的には最後に出てくるフリクション ログというのが初耳だった。フリクション = 摩擦、抵抗 の意味で、本書ではソフトウェアやサービスの利用時にうまく使えなかったことや、違和感などを示している。ユーザーに代わって自分自身がソフトウェアを試して体験を記録し、そのときに感じた違和感やイライラがドキュメントやソフトウェアの改善のヒントになる。
フリクション ログの例(「CHAPTER 1 読み手の理解」より引用)
機能品質と構造品質
CHAPTER 9 ドキュメントの品質測定 より。
ドキュメントの品質を測定する前に、まず「品質」の定義から始める必要があります。幸いなことに、Google の執筆者とエンジニアのグループがまさにこの質問に取り組んでいました。つまり、コード品質の評価と似た方法によって、ドキュメントの品質を測定していたのです※60。彼らの作成したドキュメントの品質の定義はとても簡単です。
ドキュメントが優れているのは目的にかなっている場合である。
そして、ドキュメントの品質を機能品質と構造品質に分類し、以下のように定義している。
機能品質:ドキュメントの目的やゴールが達成されているかどうか
構造品質:ドキュメント自体がうまく書かれているか、うまく構成されているか
ここで重要なのが、機能品質と構造品質では機能品質のほうがより重要であるということ。ドキュメントとしていかに上手にかかれていたとしても、目的やゴールが達成されない限りは良いドキュメントとは言えないということになる。
ドキュメントの品質をどう測定するか
同じく CHAPTER 9 ドキュメントの品質測定 より。
また、少なくとも次の質問に応えられるようにすべき。
なぜ測定したいのか?
その情報を使って何をするのか?
その努力で、どのように組織のゴールを前に進められるのか?
ドキュメントの保守:いかにして新鮮な状態に保つか
CHAPTER11 ドキュメントの保守と非推奨化 より。
あと面白かったトピックとしては
ドキュメントオーナーを決める
ドキュメントの責任は全員にある、と考えられることが多くあります。それゆえに、誰も責任を負ってないとも言えるでしょう。そこで、ドキュメントの課題への対応、ドキュメントの変更に対するレビュー、必要であればドキュメントの更新に責任をもつドキュメントオーナーを明示的に任命することで、責務を明確にしてください。責務の明確化は、ドキュメントが古くなることの防止に役立ちます。
コンテンツの鮮度確認
ドキュメントが大規模になると知らず知らずのうちに情報が古くなることもあるので、コンテンツを確認する予定日を決めておくという手もある。たとえばGoogle では、ドキュメントの上部に次のようなメタデータ を埋め込んでおくことで、コンテンツが現在でも正確かどうか確認するようなリマインダーを飛ばすしくみがあるらしい。
<!--
Freshness:{owner:“karthik”reviewed:2021-06-15}
-->
リンクチェッカー
ドキュメント内で大量にリンクされてるといつの間にかリンク切れが発生するので、それを防ぐリンクチェッカーというツールがある。本書で紹介されているのは htmltest というもの。よさそう。
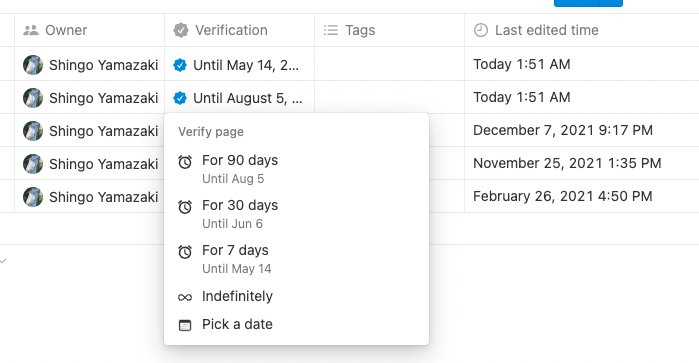
ドキュメントオーナーと鮮度確認の話を読んで、Notion に最近追加された Wiki 機能を思い出した。
Wikiとページの有効性確認 – Notion (ノーション)ヘルプセンター
まだ自分では使いこなせていないんだけど、Verification というのが「このページは○日間は新鮮な情報です!」という意思表示をすることで、読み手に今も有効なドキュメントかどうか示すことができるし、期限切れ時に通知がくるので最新かどうかチェックする役目も果たせる。(○日までは新鮮!って言ってもそれまでに情報が古くなってる可能性は全然あるんだけど、ないよりまし的な)
気に入った一節
可能ならば、よく報告される課題と顧客からのフィードバックのトレンドを理解するために、サポートチームと密に連携しましょう。顧客が同じ課題に何度も遭遇しているなら、ドキュメントまたはプロダクトを更新することで、その課題を解決する必要があります。
CHAPTER8 フィードバックの収集と組み込み より。
問い合わせ対応ってプロダクト開発における割り込みタスクとして敬遠されがちだったり、専門チーム作ってそっちに任せるのが定石っぽくなってるけど、やっぱりお客様から一番最初にいただく声ってプロダクトやドキュメントの改善の種としてはものすごい財産なんだよなー、だからチーム分けるにしてもそこをうまくつないであげる必要があるよなー、みたいなことを考えていた。ドキュメント関係ない。
余談
読書メモの残し方はこの2つの記事を参考にした。
前者を真似してメモを残す作業をやらなかったら絶対記憶に残らない本になってたと思うし、後者の気に入った一節を探す作業も「んーどこが一番お気に入りだったかな」って考えながらハイライト箇所を行ったり来たりして楽しかった。
参考リンク








」バッテリー2000mAh 子供向けGPS 日本PTA推薦商品 迷子防止の小型GPS ストラップ・充電ケーブル付き (グリーン)")


")