という記事の存在を知り、読んだところ非常に面白かったので内容のメモ。
自分がこの記事を知るきっかけになったのは X のこちらのポスト だが、X を検索すると記事自体は1年以上前からあったぽい。
(記事には公開日は明記されていない)
なかなかに文量が多く、かつSREの知識が十分ではない自分にはところどころ理解が難しい部分があった。
NotebookLM に頼りつつ内容をまとめているが、間違いを含んでいるかもしれない。
先にまとめ
重要だと思ったポイント
- 従来のサービスベースでのSLOには限界がある。サービスはユーザーニーズやビジネスゴールの部分的な解決策に過ぎず、UIとの間に複数のレイヤーが存在するためプロダクト全体をカバーできない
- これらの限界を克服するために、Google SREチームはプロダクトとエンドユーザーのニーズに焦点を当てた「プロダクトサポートモデル」を導入している。このモデルでは、SREは個々のサービスではなく、プロダクトの重要な機能とユーザーの成果に対して責任を負う
- プロダクトサポートモデルは、ユーザーがプロダクトを通じて達成したい目的(user objectives)と、目的達成のためのステップを定義し、機能の重要度に応じて適切なSLOを選択することが重要
- ユーザーの目的やステップを言語化するためのフレームワークとしてはCritical User Journey(CUJ)などがあるが、一番重要なことはプロダクトマネージャーやUXデザイナーなどエンジニア以外のステークホルダーも巻き込んで一緒に作っていくこと
背景
(NotebookLMによる要約)
従来のサービスサポートモデルでは、SREはサービスレベル目標(SLO)に基づいてサービスを間接的にサポートし、サービスの信頼性を向上させることに責任を負っていました。しかし、このアプローチには以下のような限界があり、製品やエンドユーザーのエクスペリエンスに影響を与える可能性があります:
- サービスはユーザーニーズやビジネス目標の部分的な解決策に過ぎず、サービス信頼性の測定はユーザーニーズやビジネス目標の近似に過ぎない。
- ユーザーインターフェース(UI)が複雑化しており、UIとSREが測定するサービスの間には多くのレイヤーが存在し、製品全体のカバレッジに大きなギャップが生じている。
- サービスの成長が組織のエンジニアリングの成長を容易に上回り、サービスが無視されたり、チームが過負荷になったりする可能性がある。
- サービスサポートは製品全体の信頼性とパフォーマンスのごく一部しか最適化せず、これらのサービスの範囲外に重要なリスクが存在する。
- サービスは本質的に同期型であり、非同期フローは単一のサービスで成功を測定できないため、見落とされたり、優先順位が低くなったりすることが多い。
これらの課題に対処するため、一部のGoogle SREチームは、インフラストラクチャやサービスに集中するのではなく、製品とエンドユーザーのニーズに焦点を当てたサポートへと再調整しています。この「プロダクトサポートモデル」では、SREはサービスの信頼性ではなく、製品の重要な機能の信頼性に対して責任を負います。これにより、SREチームはビジネスとユーザーの成果に合わせて優先順位をつけ、サービススタックのより広範囲で影響力の大きい取り組みに取り組むことができます。
Product-Focused Reliabilityを実現するためのステップ
以下4つのステップが紹介されている。各ステップでやることと成果物を先にまとめる。
| ステップ (Step) | やること | 成果物 (Deliverable) |
|---|---|---|
| 1. ステークホルダーとの連携 (Engage your Stakeholders) | 関連するすべての関係者を特定する。各役割の担当者を文書化する(例:RACIマトリクス)。各ステークホルダーと会合を持ち、SREとの連携を開始する。 | 役割と責任の文書化(例:RACIマトリクス) |
| 2. プロダクトのモデル化 (Model the Product) | ユーザーがプロダクトを利用して達成したい現実世界の目標(ユーザーの目的 user objectives)を理解する。ユーザーの目的を達成するための個々のステップ stepsを特定する。 必要に応じて、プロダクトマネージャーと協力してユーザーの目的のリストを作成する。ユーザーの目的とステップの高レベルな記述を含むプロダクトレジストリを作成する。 |
ユーザーの目的とステップのプロダクトレジストリ |
| 3. パフォーマンスの測定 (Measure Performance) | プロダクトの信頼性を測定するためのSLO(サービスSLO、クライアントサイド計装、エンドツーエンドSLO)を検討する。ユーザーの目的を中心にプロダクトレベルのSLOを定義する。 | 優先順位付けされたプロダクト SLO のリスト (A prioritized list of product SLOs)(可用性、レイテンシ、異なる計測方法を含む) |
| 4. 信頼性の管理 (Manage reliability) | 小規模からプロダクトSLOのサポートを開始する(例:単一の目的またはステップといくつかのSLO)。ステークホルダーと協力して、測定指標の改善、サポートする目的の拡張、パフォーマンスギャップの対応の間の投資のトレードオフを決定する。 |
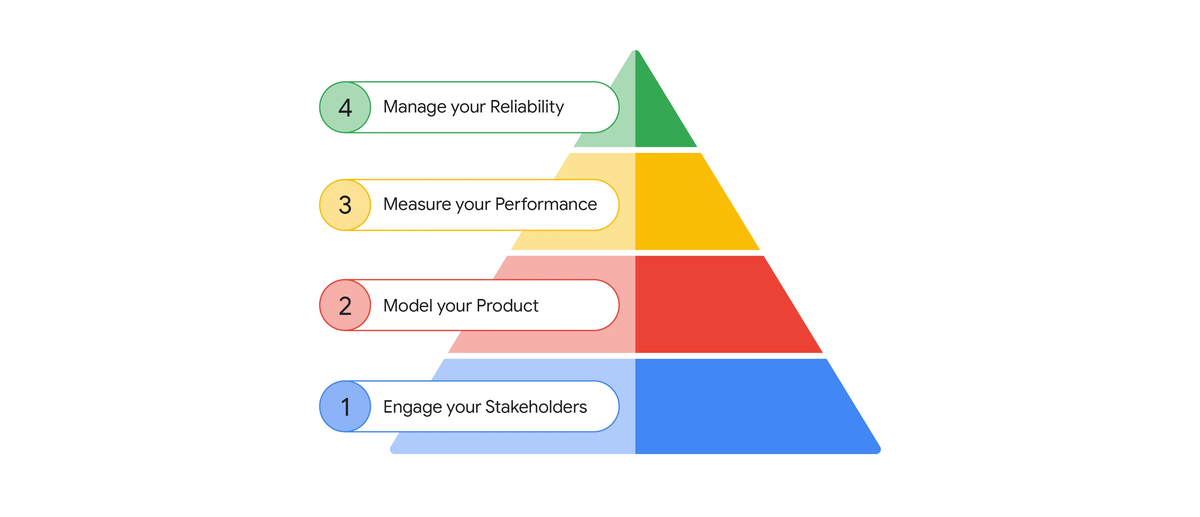
1. ステークホルダーとの連携 (Engage your Stakeholders)
- サービスベースの取り組みがSREと開発チーム間の連携に依存するのに対し、プロダクトに焦点を当てた取り組みはより多様なパートナーを必要とする。たとえば
- PdM
- UXデザイナーやリサーチャー
- エンジニアチーム
- サポートスペシャリスト
2. プロダクトのモデル化 (Model the Product)
- キーになるコンセプトはユーザー目的(user objectives)と、目的を達成するためのステップ(steps)
- ユーザー目的とステップを整理するためのフレームワークとして紹介されてるのは2つ
- Jobs to be Done (JTBD)
- Google's Critical User Journeys (CUJs)
- ユーザー目的のリストがなかった場合、SREだけで作ろうとすると多大なエンジニアリングコストを伴うし、SREのみが利用に関心を持つリストとなるだろう。より良いアプローチは、製品がエンドユーザーのニーズを満たす責任を負うプロダクトマネージャーと協力し、彼らにこれらのフレームワークのいずれかを導入し、ユーザーの目的の定義を自分たちの責任とするよう働きかけること
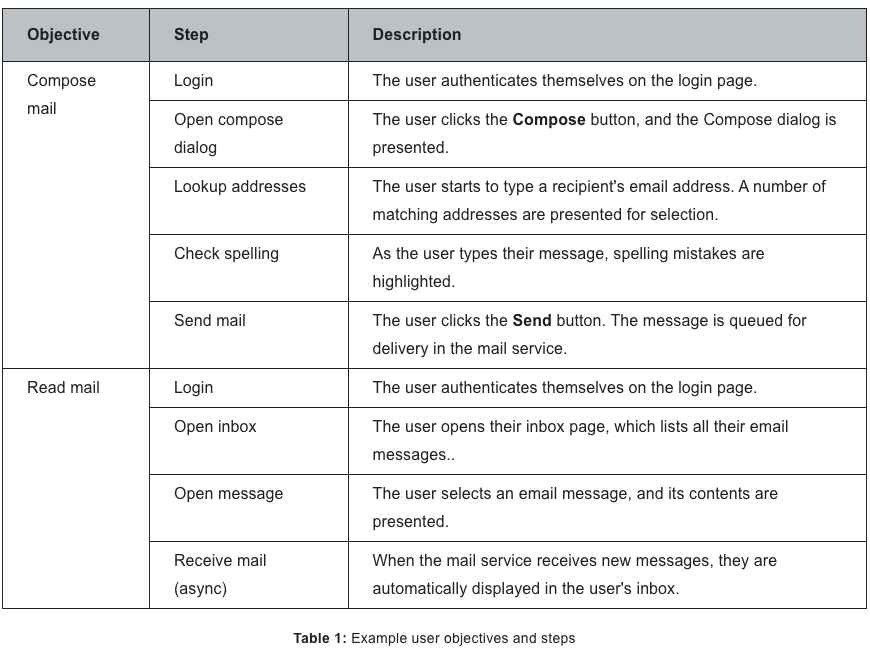
- ユーザー目的は、その目的を達成するためにユーザーが取るステップのリストに分解される。各ステップは独立したunit of workになる。ステップは次のような情報を提供してくれる
- ユーザーがプロダクトを使って何をするのか、の説明
- 各ステップの開始条件や成功/失敗条件
- 製品のインターフェースまたはインフラストラクチャに関連付けることができる具体的な行動のリスト、たとえば、ユーザーがメールを送信する際に呼び出されるRPCなど
ユーザー目的とステップの整理については、記事中で紹介されているメールサービスを例にした表がわかりやすい。
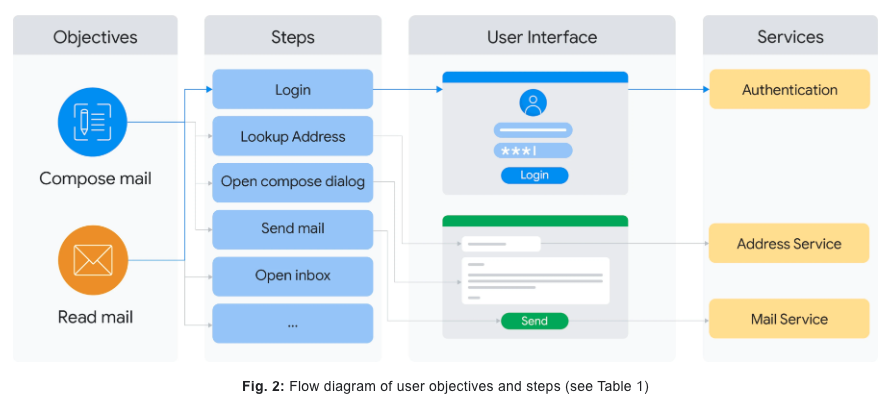
ここからさらに、各ステップとユーザーインターフェースやサービスがどのように結びついているのかを図示したものがこれ。
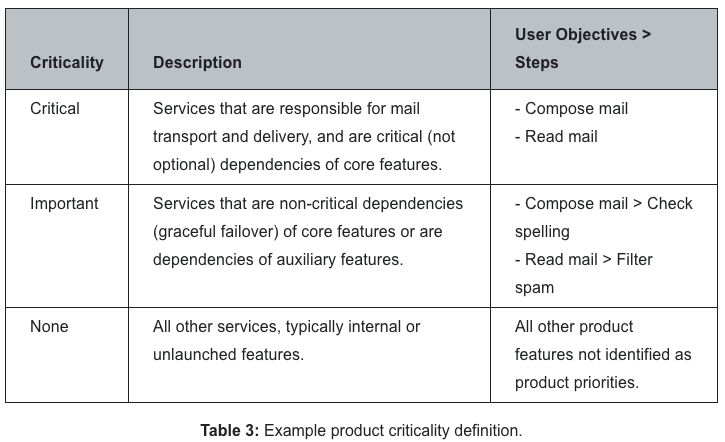
- Product criticality and prioritization
- criticality = 重要度、severity = 重大度
- ユーザー目的とプロダクトのKPIとの関係にもどつきSREのタスクの重要性を判断する
- Googleでは、サービスの停止による影響度を示すために、重大度(Severity)ガイドラインを定義している
- 重大度ガイドラインは多くの場合ユーザーへのインパクトという観点で記述されるので、ユーザー目標やステップと密接に対応する
- 重大度ガイドラインを使用すると、重大な停止が製品や機能に与える影響(製品の重要度(criticality)として定義される)に基づいて、ユーザーの目標や手順を整理できる
- この重要度の定義は、SREの仕事の優先順位付けにおける明確なガイドラインを提供する
重要度について、ここでもメールサービスの具体例がある。
3. パフォーマンスの測定 (Measure Performance)
- SLOは、システムの信頼性を反映する具体的な指標を提供する、SRE チームにとっての重要な要素
- サービスベースのSLOでは十分なプロダクトカバレッジが提供されない。単一のサーバーから測定できない類の問題がある。たとえばWebやモバイルアプリ内、あるいは非同期アクションを通じて発生する問題など
- 製品をより広範囲にカバーする SLO には、サービス SLO、クライアントサイドインストルメンテーション、エンドツーエンド SLO の 3 つの主なカテゴリがある
- サービスSLO (Service SLOs)
- 最も一般的なSLO
- アプリケーションサーバーのログやライブモニタリングのメトリクス、ロードバランサーのログ、ブラックボックスモニタリングの結果など、サービス自体またはサービスより上位のレイヤーから取得された測定値に基づいて計測される
- クライアントサイド計装 (Client-side instrumentation)
- Webアプリケーションやモバイルアプリケーションなどのユーザーインターフェースから直接テレメトリーを取得することで実現される
- エンドツーエンドSLO (End-to-end SLOs)
- サービスやクライアントサイドの計測では直接測定できない製品機能やビジネス指標を測定するために使用される。多くの場合、複数のソースからのデータを結合し、非同期タスクを追跡する
- 例:
- ユーザーはレポートを生成したい。UIはRPCリクエストを送信し、システムにenqueueされるが、それ自体はレポートの作成に成功したことを意味しない。バックエンドのシステムがdequeueしレポートを生成することで成否が決まる
- このような場合のエンドツーエンドSLOとして考えられるのは、以下のようなメトリクス(本文中に明言されてないが、以下NotebookLMの提案が個人的には納得感あった)
- レポート生成成功率: ユーザーがレポート生成を要求してから、実際にレポートが生成され、ユーザーがアクセス可能になるまでの成功した割合。これは、単にレポート生成のリクエストが受け付けられたかどうか(サービスSLOの範疇)だけでなく、最終的な成果を測るものです。
- レポート生成完了までの時間: ユーザーがレポート生成を要求してから、実際にレポートが生成完了するまでの時間。これは、非同期処理の完了までの時間をユーザー視点で捉えるものです。
- 特定期間内のレポート生成エラー率: 特定の時間帯に発生したレポート生成の失敗数を、全レポート生成要求数で割った割合。これにより、ユーザーが実際にレポートを利用できない状況を把握できます。
それぞれの特徴を表にまとめると以下のようになる。
| サービスSLO | クライアントサイド計装 | エンドツーエンドSLO | |
|---|---|---|---|
| コスト | 低い | 中程度 | 非常に高い |
| 信頼(confidence) | 高い | 低い | 高い |
| レイテンシ | 低い | 中程度 | 高い |
| カバレッジ | 狭い | 広い | 狭い |
エンドツーエンドSLOのカバレッジが狭いというのは、エンドツーエンドSLOは非常に具体的な機能をカバーすることが目的になっているから。
最終的に、ユーザー目的とステップ、それにプロダクトの重要度を加味して、最適な測定方法とSLOの数値目標を決めることになる。
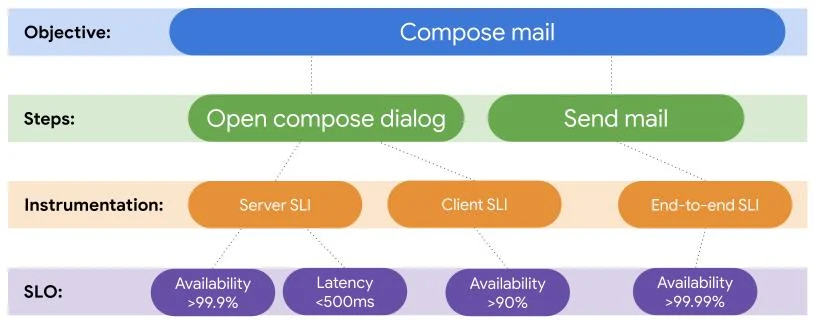
たとえば重要度の高いユーザー目的とステップには、「高コストだが正確なエンドツーエンドのSLOで計測する」という選択肢が考えられる。逆に重要度が低い、コアではない機能については従来通りの低コストなサーバーベースのSLOでサポートする、といった判断がなされる。
4. 信頼性の管理 (Manage reliability)
- 小さく始める。単一のユーザー目的またはステップといくつかのSLOから、など
- プロダクトSLOは継続的に繰り返すプロセス
- 以下3つの領域に対してどういった割合で投資するのかを、ステークホルダーと決定する
- メトリクスの改善(すでに計測しているものの信頼性を向上する)
- サポートするユーザー目的の拡大
- 1と2で明らかになったパフォーマンスの問題に対処
感想
ちょうど近い悩みを職場で話していたので非常に学びがあった。
インシデント対応とかをやっている中で、「こういうシステムアラート出てるんですけど、これで実際どれくらいユーザー体験を毀損してるのかわからないんですよねー。。。」みたいな。
システムを主体としたメトリクス、SLOではなく、ユーザーがプロダクトを使う目的(提供する価値、と言い換えてもいいと思う)に根ざしたSLOを定義してモニタリングしていけるといいよね、はすごい同意できるし、できたらめちゃくちゃかっこいい。
CRE の実現のしかたの1つでもあるんじゃないかとも思った。
一方で、非常にハードルの高い取り組みだなとも感じた。
ユーザーの目的からブレイクダウンしてSLOを定義するのも、それを計測可能にするのもかなり難易度高そう。
特に前者は最初からきれいな形でやろうとすると形にするのに非常に時間と労力がかかりそう。
だからこそ「4. 信頼性の管理 (Manage reliability)」にも書いてあったように、まず1つの目的から、というように小さく初めて育てていく取り組みが重要なんだと思う。また、これらをエンジニアだけの取り組みにするのではなく、プロダクトチームあるいはビジネスサイドも巻き込んだ活動にするのが大事。とってもチャレンジングだけど。