みんなのデータ構造(紙書籍+電子書籍) – 技術書出版と販売のラムダノート

これまでのメモ
2章の後半をすっ飛ばして、第3章の連結リストに入る。
今回は「[P55] 3.1 SLList: 単方向連結リスト」。
TypeScript によるソースコード
https://github.com/zaki-yama/open-data-structures-typescript/blob/master/src/SLList.ts
みんなのデータ構造(紙書籍+電子書籍) – 技術書出版と販売のラムダノート
これまでのメモ
2章の後半をすっ飛ばして、第3章の連結リストに入る。
今回は「[P55] 3.1 SLList: 単方向連結リスト」。
TypeScript によるソースコード
https://github.com/zaki-yama/open-data-structures-typescript/blob/master/src/SLList.ts
引き続き、「みんなのデータ構造」という本を読む。
みんなのデータ構造(紙書籍+電子書籍) – 技術書出版と販売のラムダノート
これまでのメモ
今回は「P35. 2.4 ArrayDeque 配列を使った高速な双方向キュー」。
TypeScript によるソースコード
https://github.com/zaki-yama/open-data-structures-typescript/blob/master/src/ArrayDeque.ts
新しいTrailhead Playgroundがリリース。パッケージのインストールやパスワードリセットがTrailhead組織にプリインストールされたアプリから簡単にできるようになった、かな #sfdg /Get Hands-On with the New and Improved Trailhead Playground https://t.co/224Zjfo9OK
— Shingo Yamazaki (@zaki___yama) 2020年1月17日
新しいTrailhead Playgroundがリリースされました。
といっても劇的なアップデートではなく、Playgroundにアプリが1つプリインストールされるようになっただけのようです。
今まで通り、ハンズオン形式の問題から「Trailhead Playgroundを作成」で作成すると、新しい組織にはプリインストールされるようになっています。
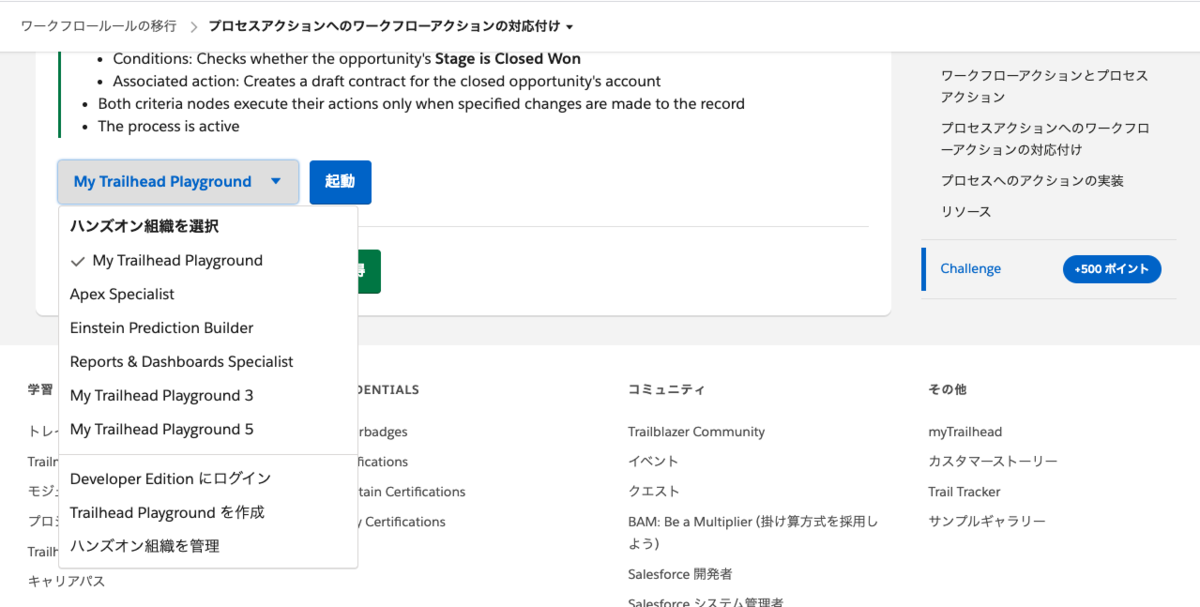
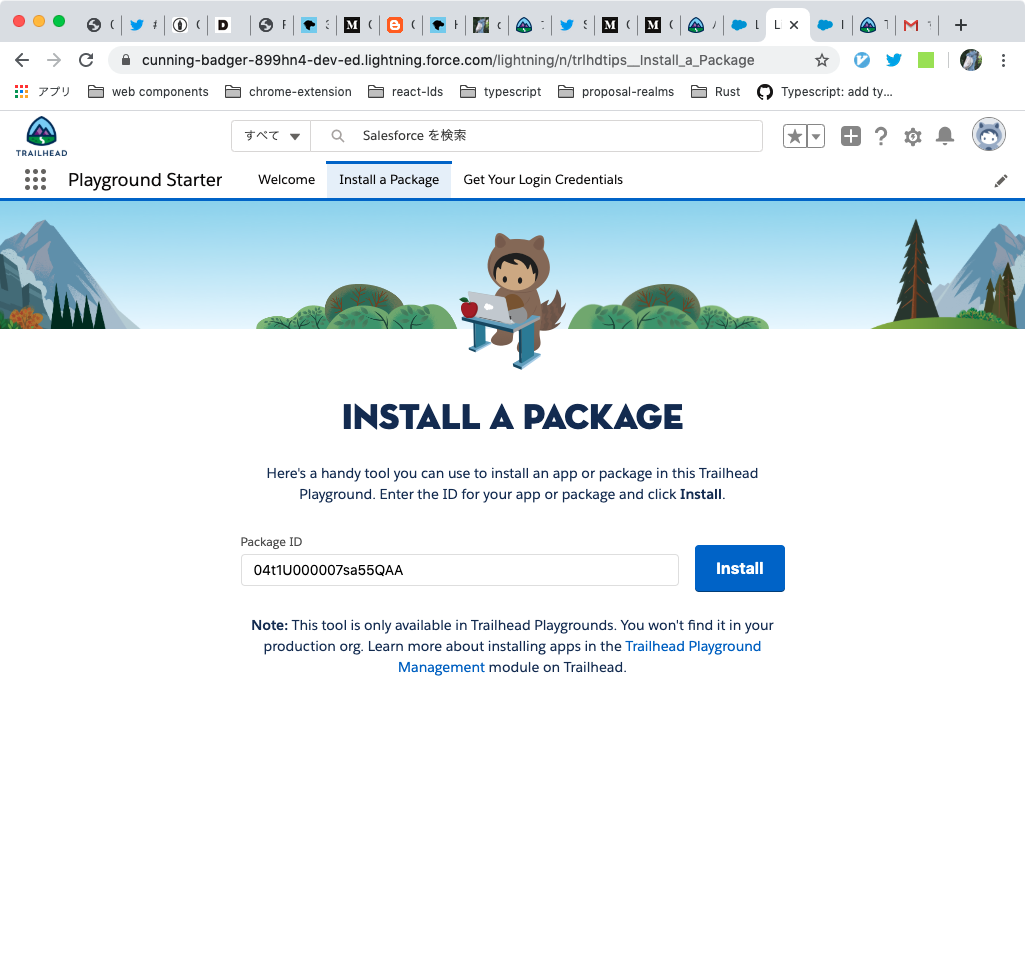
「Install a Package」タブからは、パッケージIDを入力してボタンを押すとパッケージをインストールできるようになります。
単に別タブでインストール画面が開くだけですが、これまではこのためにログインを求められてパスワードが必要だったはずなので手間が減ったかな。
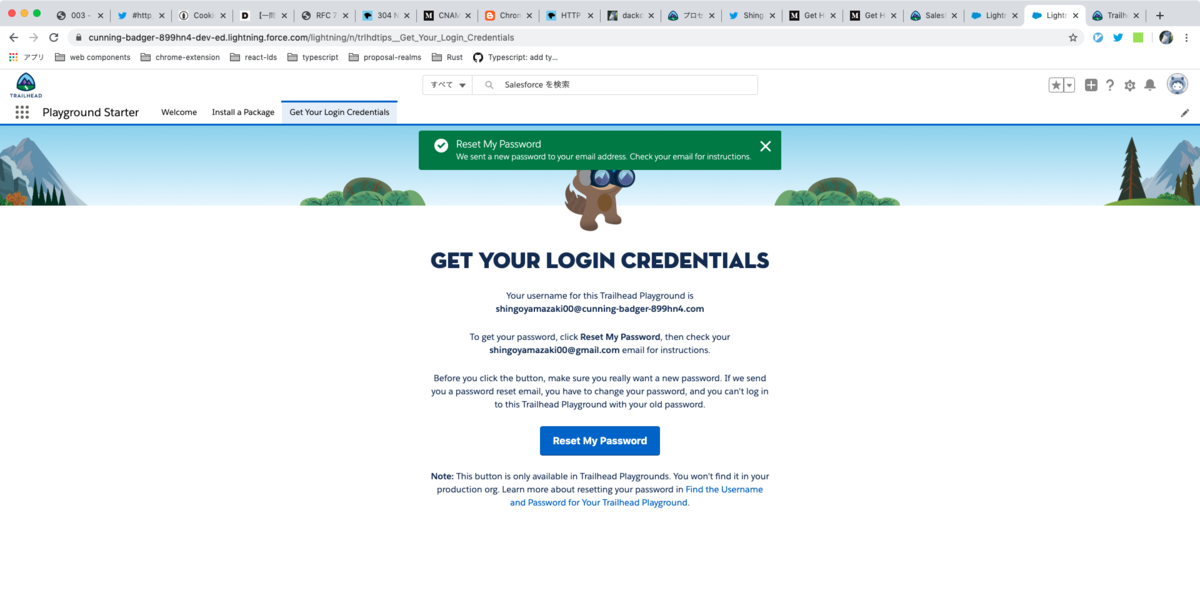
「Get Your Login Credentials」からはユーザー名が確認できるほか、パスワードのリセットが可能です。
この場で新しいパスワードを入力させてもらえるのかと思いましたが、単にリセットが行われてメールが送信されるだけのようです。
すでにTrailheadのモジュール内で、パッケージインストール手順やパスワードリセット手順などの記述はアップデート済みっぽい。(全部じゃないかもしれない)
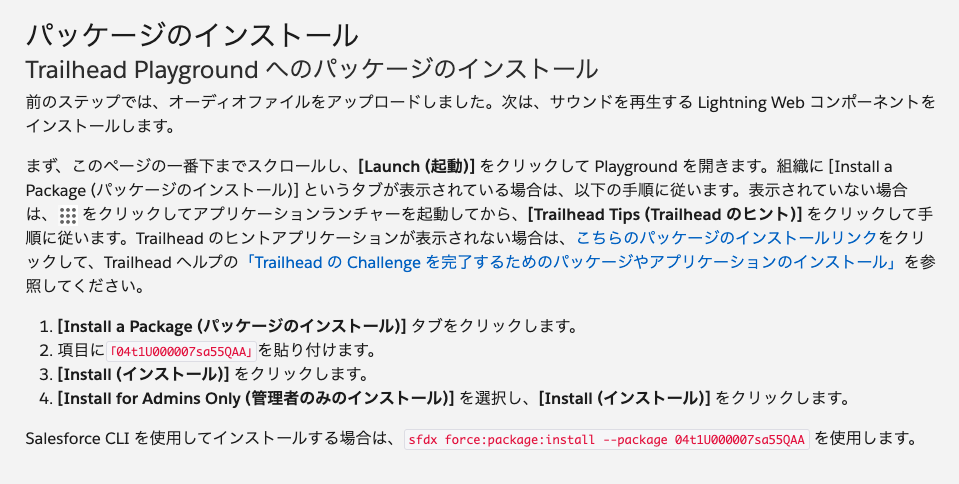 (Salesforce 組織へのサウンド効果の追加 > パッケージのインストール)
(Salesforce 組織へのサウンド効果の追加 > パッケージのインストール)
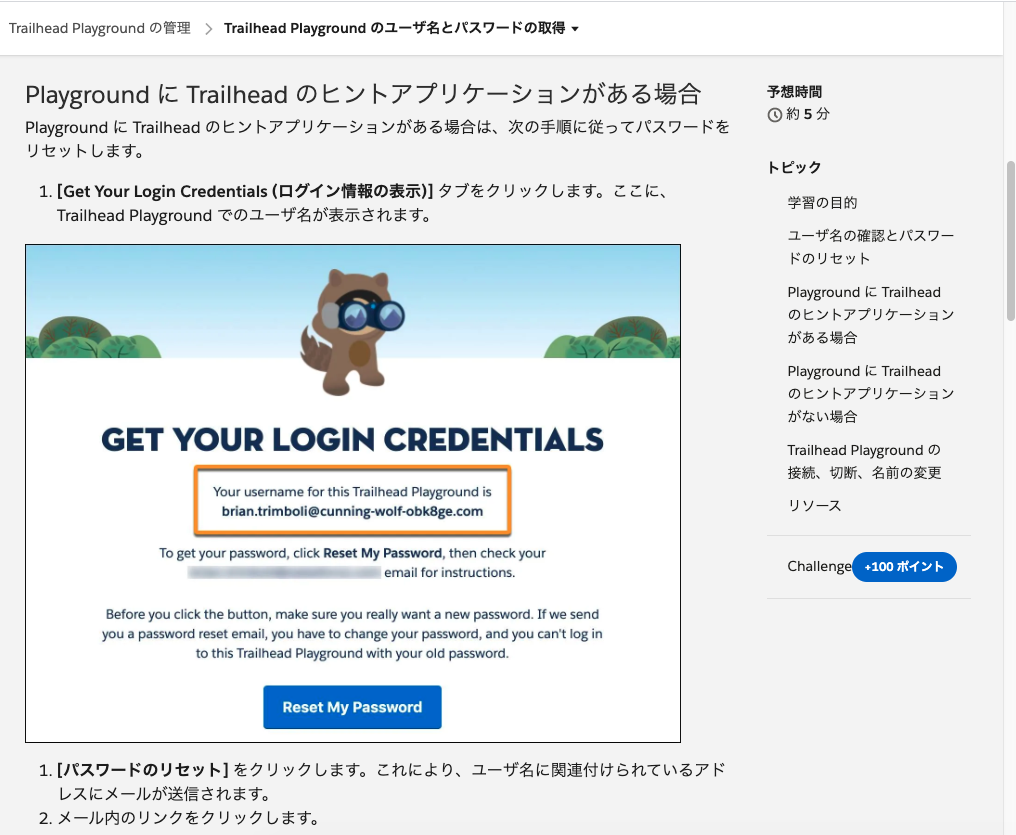
(Trailhead Playground の管理 > Trailhead Playground のユーザ名とパスワードの取得
こちらの記事を読んで、自分でも試してみたメモ。
ヘルプ
認証プロバイダについては
10分でできる!SalesforceでSSO(認証プロバイダ:Google編) - TECH BLOG | 株式会社テラスカイ
などの記事にあるように、外部サービスのアカウントを使ってSalesforceへのSSOを実現することができる機能。
今回は単純にConsumer KeyやSecretといったクレデンシャル情報を登録するためだけに使う。
指定ログイン情報については、APIエンドポイントと必要な認証パラメータを登録しておくことで、登録した外部サービスのAPIをSalesforceから叩く際に面倒な認証認可のフローを肩代わりしてくれる機能。
認証プロバイダは英語だと「Auth. Providers」。
新規で作成しようとすると、プロバイダタイプにTwitterやGitHub、Googleなど主要なサービスがデフォルトで存在することがわかる。

サービスごとに認証方式が異なるので必要な入力事項も異なるが、そこはフォームが動的に変化してよしなにやってくれる。
今回はプロバイダタイプにGitHubを選んだ。

「コンシューマ鍵」と「コンシューマの秘密」はまだ発行してないので、この時点では適当な文字列を入れておく。

保存すると「Salesforce設定」というセクションにいくつかURLが記載されている。
このうち、「コールバックURL」はこの後Consumer Key/Secret を発行する際に入力するのでコピーしておく。
GitHubの場合、Settings > Developer settings > OAuth AppsからNew OAuth Appを選ぶと作成できる。

「Authorization Callback URL」に先ほどのコールバックURLを入力する。
また、発行した Consumer Key/Secret で先ほどの認証プロバイダの設定を更新する。

URLはAPIのエンドポイントとなる。GitHubの場合は https://api.github.com 。
ID種別は「指定ユーザ」、認証プロバイダで先ほど登録したGitHub用の設定を選択する。
(ID種別については後述)
今回は Apex で試してみる。
このようなコードを書く。
HttpRequest req = new HttpRequest(); req.setEndpoint('callout:github/repos/zaki-yama/copy-title-and-url-as-markdown/issues'); req.setMethod('GET'); Http http = new Http(); HTTPResponse res = http.send(req); System.debug(res.getBody());
setEndpoint() に指定する文字列は
callout:<指定ログイン情報の「名前」>/指定ログイン情報の「URL」以下のパス>
となる。
今回使用した「指定ユーザ」以外に、「匿名」と「ユーザ」がある。
ヘルプによれば

外部システムへのアクセスに 1 セットのログイン情報と複数セットのログイン情報のどちらを使用するかを決定します。
外部システムへのアクセスに 1 セットのログイン情報と複数セットのログイン情報のどちらを使用するかを決定します。
- 匿名: ID がないため、認証は行われません。
ユーザ: コールアウトから外部システムにアクセスするユーザごとに、別個のログイン情報を使用します。このオプションは、ユーザ単位で外部システムのアクセスを制限する場合に選択します。 Salesforce の権限セットまたはプロファイルを使用してユーザアクセスを付与したら、ユーザは個人設定で外部システムの独自の認証設定を管理できます。JWT または JWT トークンの交換を使用している場合、それらに対して、ユーザごとのログイン情報が処理されます。
指定ユーザ: 組織から外部システムにアクセスするすべてのユーザに対して、同じセットのログイン情報を使用します。このオプションは、すべての Salesforce 組織ユーザに外部システムの 1 つのユーザアカウントを指定する場合に選択します。
とあるので、外部サービス側でもSalesforceユーザごとにアカウントを区別したい場合は「ユーザ」を指定しつつユーザごとに追加の設定が必要になりそう。
行ってきました。
中身の濃い勉強会で非常に勉強になった。
jxckさんの発表は圧巻でした。
資料: https://slides.araya.dev/http-tokyo-1/#slide=1 demo: https://playground.araya.dev/http-redirections/
資料: https://www.slideshare.net/yuki-f/status-425-httptokyo
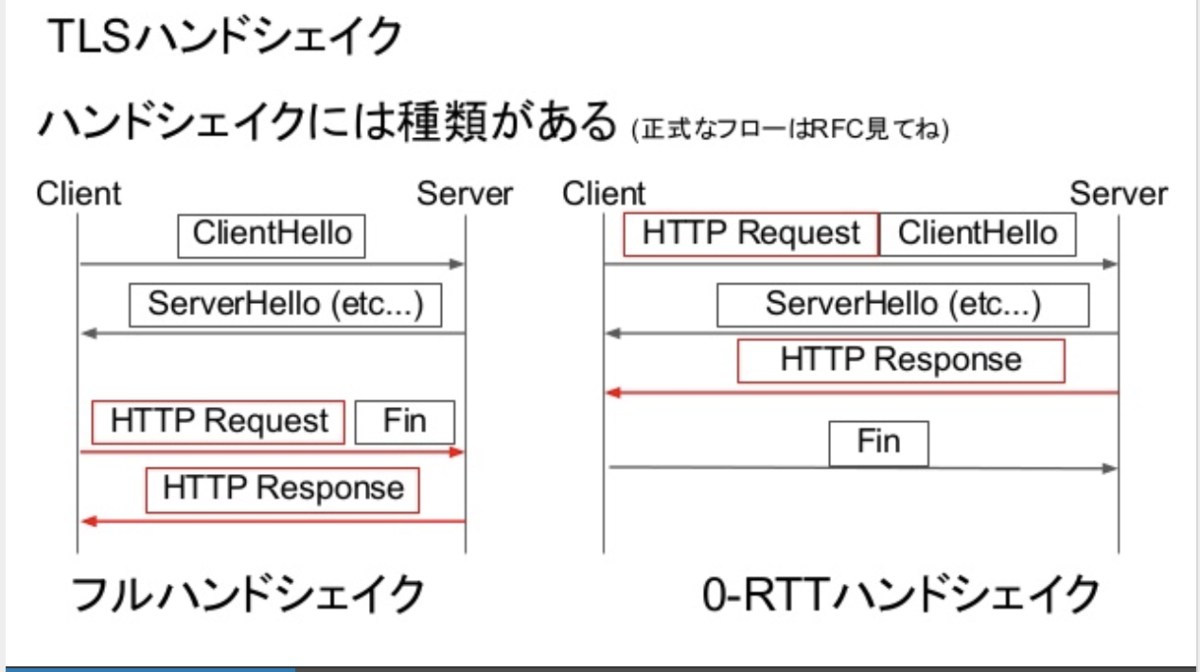

Early-Data: 1というヘッダーをつけてoriginに送る資料はなし。ホワイトボードを使って説明。
Set-Cookie するときに、idの後ろに SameSite: というプロパティを付けることができるようになったSec-Http-State: token=XXX引き続き、「みんなのデータ構造」という本を読む。
みんなのデータ構造(紙書籍+電子書籍) – 技術書出版と販売のラムダノート
前回
今回は「P32. 2.3 ArrayQueue 配列を使ったキュー」。
続きを読む「みんなのデータ構造」という本を読み始めたので、その読書メモを。
今回は 2.1 節の「ArrayStack」というデータ構造について。
https://sites.google.com/view/open-data-structures-ja/home より引用。
Open Data Structures は Pat Morin 氏が執筆した、データ構造の入門書です。本プロジェクトでは、この本の和訳を作成し、PDF ファイルおよびそのソースコードを公開しています。
データ構造やアルゴリズムについて学びたいと思っていたので、この本で勉強することにした。
PDF版であれば日本語でもフリーで手に入るが、私はラムダノート社のサイトから紙書籍+電子書籍版を購入した。
みんなのデータ構造(紙書籍+電子書籍) – 技術書出版と販売のラムダノート
また、書籍内のサンプルコードはC++で書かれているが、C++はわからないのでTypeScriptで写経することにした。
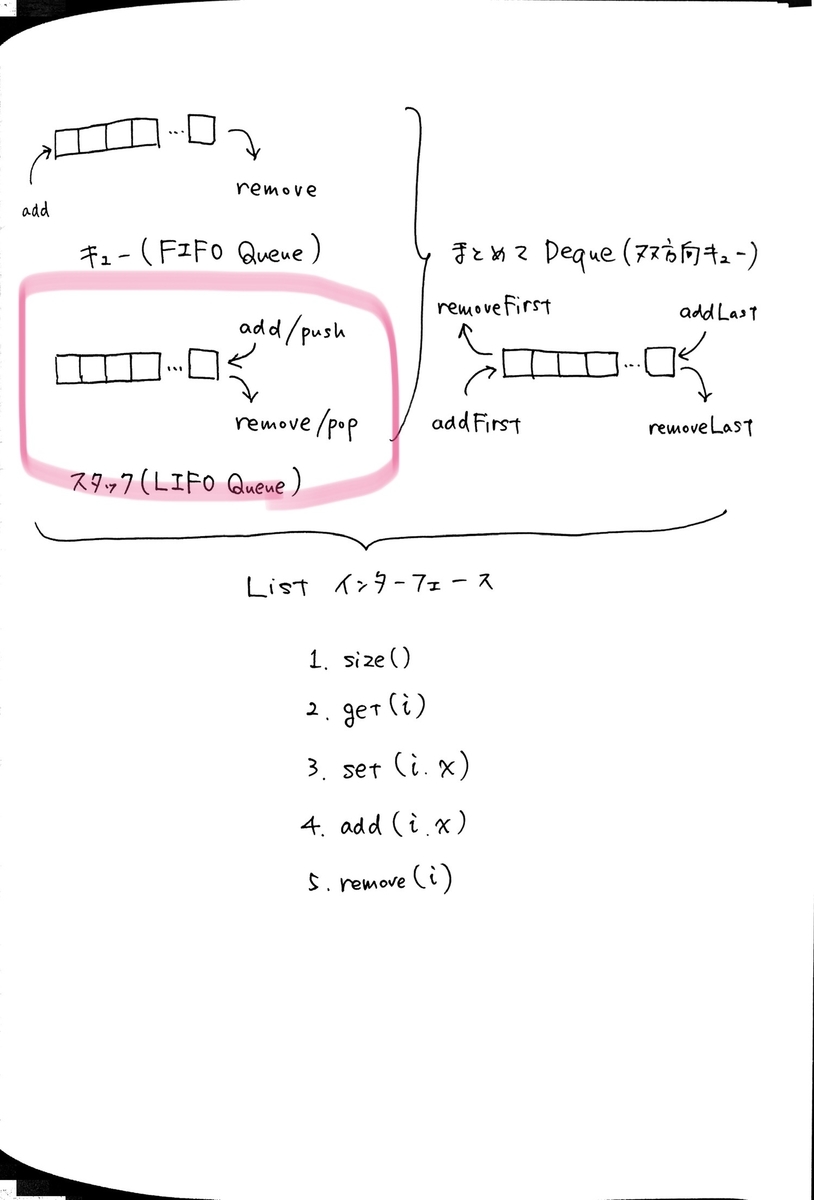
size(): リストの長さ n を返すget(i): set(i, x): add(i, x): remove(i): get(i) および set(i, x) の実行時間は O(1)add(i, x) および remove(i) の実行時間は
resize() を考慮しなければ O(n - i)resize() を考慮すると O(1 + n - i) ただしこれは償却実行時間
「償却実行時間」という言葉が出てくるが、これは「1.5 正しさ、時間計算量、空間計算量」の節に定義がある。
償却実行時間が
であるとは、典型的な操作にかかるコストが
個の操作にかかる実行時間を合計しても、
を超えないことを意味する。いくつかの操作には
要するに同じ操作を m 回やったときの実行時間から1回あたりの実行時間を考えるという話。
resize() の実行時間についてここがしばらくわからなかった。
空のArrayStackが作られたあと、
回の
add(i, x)およびremove(i)からなる操作の列が順に実行されるとき、resize()の実行時間はO(m)である。
書籍では
resize() が呼ばれるとき、その前の resize() から add/remove が実行された回数は n/2 -1 以上であるresize() の実行時間の合計は O(m) であるという2段階で説明しており、また 2 → 1 の順に証明している。
ここでは普通に1から書く。
resize() が呼ばれるとき、その前の resize() から add/remove が実行された回数は n/2 -1 以上であるresize()が呼ばれるのは、add(i, x) 内で呼ばれるケースと remove(i) 内で呼ばれるケースの2通りある。
add(i, x) 内で呼ばれる場合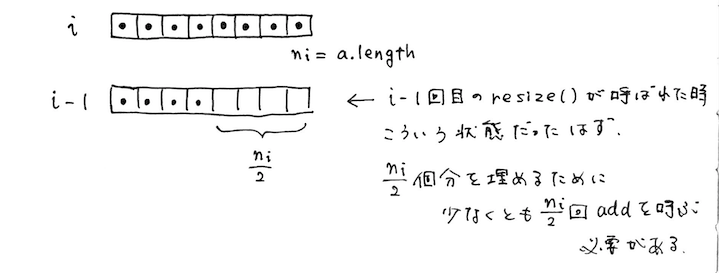
※書籍に倣って、「◯回めの resize() か」を表す◯に を使っているが、これは
add(i, x) の i とは無関係。ややこしい
この場合は i 回めの時点では配列 a は要素で満たされた状態、 i - 1 回めの時点では配列 a の長さは同じで、要素数は半分。
なので空いている a.length /2 = n_i / 2 分を埋めるのに、少なくとも n_i / 2 回の add() は実行されているはずである。
remove(i) 内で呼ばれる場合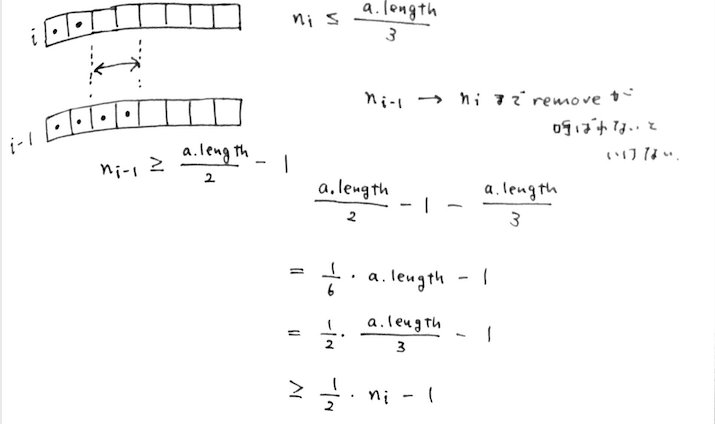
逆に remove(i) 内で呼ばれる場合、要素数 n_i が配列 a のサイズの 1/3 以下になる場合なので、 n_i <= a.length / 3。
1つ前の i - 1 回めの resize() が実行された直後の状況を考えると、このときは resize() によって配列のサイズの半分の要素数になっているはず。
n_(i-1) = a.length / 2 でもいいが、n = 0 && a.length = 1 という特殊ケースを考えると n_(i-1) >= a.length / 2 - 1 となる。
今度は要素数が n_(i-1) から n_i になるまで remove() が実行されているはずなので、差をとって↑のように式変形すると n_i / 2 - 1 以上であることが示せる。
resize() の実行時間の合計は O(m) である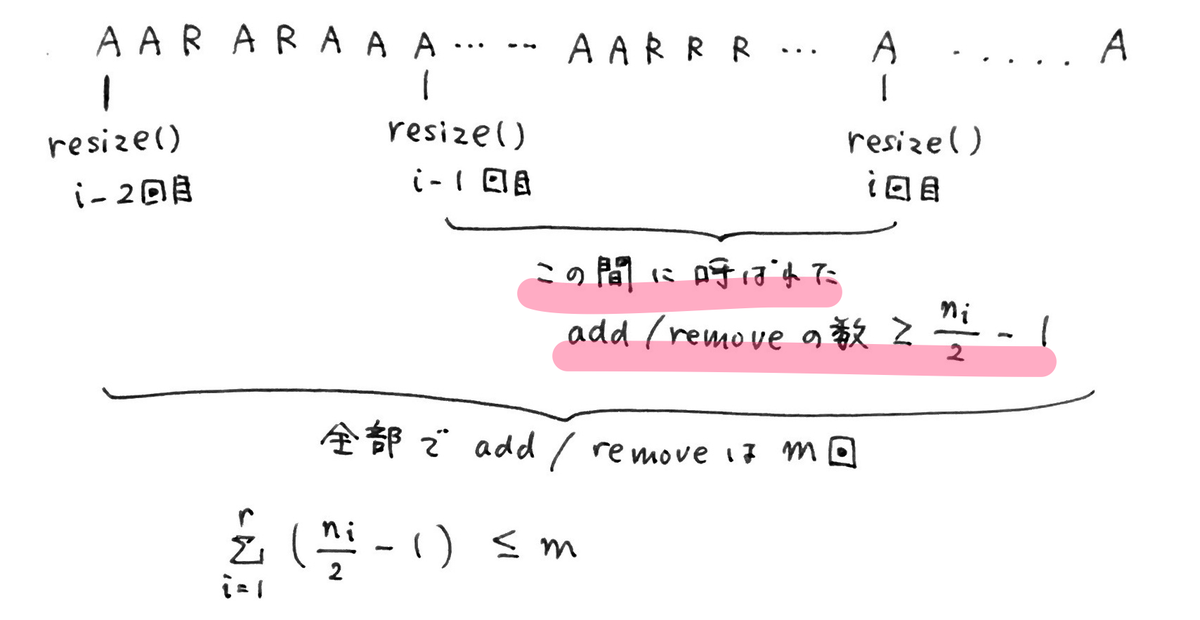
↑では、add(i, x)を A、 remove(i) を R と表現している。
いま、この AとRをランダムに実行した一連の操作があり、その操作の合計が m 回である。
またこの間に不定期に resize() が実行されており、合計で r 回実行された。
1でわかったのは色をつけた部分で、
「i - 1回めの resize() から i 回めの resize() の間に呼ばれた add/remove の数は >= n_i - 1 である」
ということ。
また、
(1回めのresize()から2回めのresize()までのadd/removeの数) + (2回めのresize()から2回めのresize()までのadd/removeの数) + ... + (i - 1 回めのresize()からi回めのresize()までのadd/removeの数) + ... + (r - 1 回めのresize()からr回めのresize()までのadd/removeの数) <= m
(r 回めの resize() の後にも何回か add/remove が呼ばれている可能性があるため)
で、かつ左辺のそれぞれの項は n_i /2 - 1 よりも大きいと言っているんだから、結局
が示せたことになる。