過去メモ
教材
")
流れ
- レイヤアーキテクチャ
- 依存性逆転の法則 (DIP)
- 上位が下位に依存する従来の形をやめ、抽象が詳細に依存するのではなく、実装が抽象に依存するべき
- 実装例:
- 依存性の注入(DI)
- サービスファクトリ
- プラグイン
- ヘキサゴナルアーキテクチャ
- ドメインを中心に捉え、入出力は差し替え可能な外部インターフェースとして扱う
- ポート&アダプタ とも呼ばれる
- サービス指向アーキテクチャ(SOA:Service Oriented Architecture)
- REST
- コマンドクエリ責務分離(CQRS:Command Query Responsibility Segregation)
- オブジェクトの状態を変更するメソッドは「コマンド」であり、値を返してはならない
- 何らかの値を返すメソッドは「クエリ」であり、オブジェクトの状態を変更してはならない
- 参照透過性
- イベント駆動アーキテクチャ
4.2 レイヤアーキテクチャ
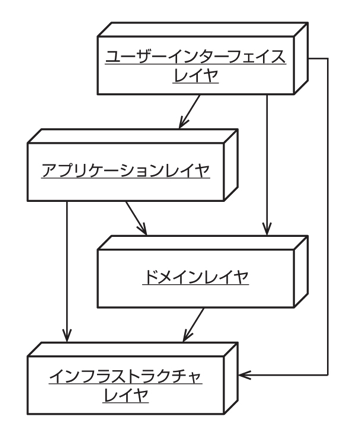
アプリケーションを関心ごとにいくつかの層に分割したアーキテクチャ。
依存関係逆転の法則(DIP)
Robert C. Martin が提唱した原則。
上位のモジュールは下位のモジュールに依存してはならない。どちらのモジュールも、抽象に依存すべきである。抽象は、実装の詳細に依存すべきではない。実装の詳細が、抽象に依存すべきである。
下位レベルのサービスを提供するコンポーネント(インフラストラクチャ)は、上位レベルのコンポーネント(UI やアプリケーション、ドメイン)が定義するインターフェースに依存すべきという考え。
以下の記事やスライドがわかりやすかった。
(スライドは依存性の注入(DI)まで言及してる)
たとえばドメイン層とインフラストラクチャ層の間で考えたとき、
と、利用するデータベースを変更することになってインフラストラクチャ層を別のクラスに置き換えようとしたときに、実装しているメソッドの名前や引数の型・数が異なると上位レイヤであるドメイン層にまで改修が必要になる。
これを、あらかじめインフラストラクチャ層のインターフェースを定め、
としておくと、下位レイヤのクラスは上位レイヤから見ていつでも交換可能となり、実装に依存しなくなる。
また上位レイヤも下位レイヤもインターフェース(抽象)に依存した状態となっている。
4.3 ヘキサゴナルアーキテクチャ
レイヤアーキテクチャではドメインに対して上位・下位という非対称な構成だったが、
「アプリケーション(ドメイン)層を中心に捉え、ユーザー操作/自動テストといった入力側もデータベース/モックといった出力側も、全てまとめて差し替え可能な外部インターフェイスとして扱う」という考え方
(http://codezine.jp/article/detail/9922?p=2 より引用)
をヘキサゴナルアーキテクチャと言う。
システムを、外部 と 内部 の二つの領域に分ける考え方だ。外部が、さまざまなクライアントからの入力を受け付ける。また、永続化されたデータを取得する仕組みを提供したり、アプリケーションの出力をデータベースなどに格納したり、メッセージングなどのその他の方法で出力を送信したりする。
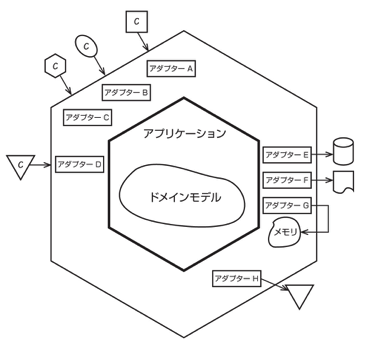
たとえば入力側としては、ブラウザからの入力や REST API でのアクセスといった異なる入力も、それぞれ専用のアダプターを用意することでアプリケーション(ドメイン)を同じように扱うことができる。
また出力側は、永続化機能として種々のデータベースに対応したアダプターを用意したり、あるいはテスト用のモックを扱うアダプターを用意することもできる。
ポートとアダプタの役割の違いや、どちらがより外側に位置するという扱いなのかはよくわからなかった。
4.6 CQRS
データの「参照(クエリ)」と「更新(コマンド)」を分解するアーキテクチャパターン。
- コマンド(ライト):オブジェクトの状態を変更するメソッドは値を戻してはいけない。戻り値の型は void
- クエリ(リード):メソッドが何らかの値を返すのなら、オブジェクトの状態を変更してはいけない
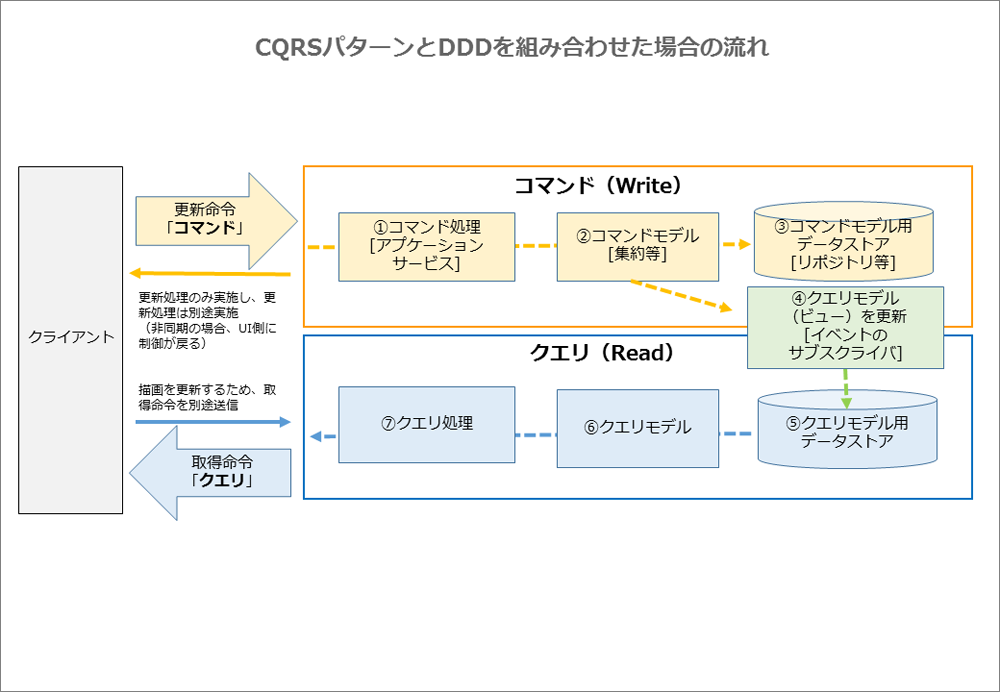
CQRS についてはこの記事が非常にわかりやすかった。
CQRSとイベントソーシングの使用法、または「CRUDに何か問題でも?」 | プログラミング | POSTD
図を見てもわかるように、クエリモデル用とコマンドモデル用で別々のデータストアを用意することもできる。
CQRS のメリット
参照の際は、ユーザーのロール(一般ユーザー、マネージャー、管理者)に合わせて必要な別々のクエリモデルを用意しておくことができる。
表示したい内容の変更にはビューの変更だけで済む。
(現実的には RDBMS の場合、それぞれをビューとして定義しておく?)
更新の際は、「ユーザー情報を更新する」ではなく「メールアドレスを更新する」「請求先情報を変更する」というように目的に合わせたコマンドを用意することで、パーミッションチェックは特定のコマンドが実行可能かどうかだけをチェックすればよく、エンティティのどのフィールドが更新可能なのかという混乱がなくなる?
CQRSを深く考えずに実装するなら、単純にcreate、update、deleteのコマンドを用意すればよさそうです。しかしこれは、大事なことを見落としています。読み込みに使うデータモデルとコマンドを「別のもの」として明示的に切り離すということは、データを問い合わせる際に使うUserモデルとコマンドを実行するときに使うモデルとが違っていてもかまわないということです。ユーザー情報を更新するというのではなく、「メールアドレスを変更する」「請求先情報を変更する」なとどいうコマンドを考えることができるのです。CQRSなら、エンティティのどのフィールドが更新可能なのかといった混乱はなくなります。コマンドには、そのコマンドに関連するフィールドだけを含めることになるからです。パーミッションの考えかたも簡単になります。呼び出し元が変更しようとしているエンティティのフィールドが本当に変更してよいかどうかをチェックするのではなく、呼び出し元に特定のコマンドを実行する権限があるかどうかだけをチェックすればいいのです。
(http://postd.cc/using-cqrs-with-event-sourcing/ より引用)
イベント駆動アーキテクチャ
イベントを待機し、起こったイベントに応じて処理を行うプログラムスタイル。
イベントソーシング
起こったすべてのイベントを順にデータベースに保存する。銀行の取引処理なんかがそう。
ある時点から発生したイベントを順に再生することで状態がいつでも復元できるため、監査やバグ調査において有効。
また先程の CQRS と相性がよい。CQRS の記事でも言及されているので参考になる。
おわりに
第4章は紹介されている1個1個のアーキテクチャがかなり骨太な感じで、かつ DDD との関連もあまりよくわからないままざっと紹介だけされた印象を受けた。
第5章「エンティティ」も実は先日終わっているんだけど、早いとこ復習したい。
ちなみに次回は今週水曜日です。