
読みたいなと思って2年近く積読状態だった本を、会社の同僚と一緒に輪読会形式で読んだ。
自分一人じゃ挫折してたと思うので誰かを巻き込んでよかった!
本書の目次
第1章 WebとWebセキュリティ 1.1 Webを構成する基本の3つのコンポーネント 1.2 プラットフォームとしてのWeb 1.3 Webセキュリティ 1.4 サーバーサイドWebシステムのセキュリティ 1.5 クライアントサイドWebシステムのセキュリティ 1.6 まとめ 第2章 Origin を境界とした基本的な機構 2.1 Webリソース間の論理的な隔離にむけて 2.2 OriginとSame-Origin Policy(SOP) 2.3 CORS(Cross-Origin Resource Sharing) 2.4 CORSを用いないSOPの緩和方法 2.5 SOPの天敵、XSS(Cross-Site Scripting) 2.6 CSP(Content Security Policy) 2.7 Trusted Types 2.8 まとめ 第3章 Webブラウザのプロセス分離によるセキュリティ 3.1 Webブラウザが単一のプロセスで動作することの問題 3.2 プロセスを分離した場合の問題 3.3 Process-per-Browsing-Instanceモデルに対する攻撃 3.4 Process-per-Site-Instanceモデルとその補助機能 3.5 まとめ 第4章 Cookie に関連した機構 4.1 Cookieの導入の動機 4.2 属性によるCookieの保護 4.3 Cookieの性質が引き起こす問題とCookieの今後 4.4 まとめ 第5章 リソースの完全性と機密性に関連する機構 5.1 問題と脅威の整理 5.2 HTTPSとHSTS 5.3 Mixed Contentと安全でないリクエストのアップグレード 5.4 Webブラウザが受け取るデータの完全性とSRI 5.5 Secure Context 5.6 まとめ 第6章 攻撃手法の発展 6.1 3種類の攻撃手法 6.2 CSP下でのXSS 6.3 Scriptless Attack 6.4 サイドチャネル攻撃 6.5 まとめ
第6章は発展的な話題ぽかったのでスキップ。
この本について
今回は輪読会の最後にそこそこ労力をかけて書籍の内容をまとめるという活動をやった。
せっかくなので冒頭の内容をそのままこちらに記載しようと思う。
(ほんとは全部書きたいけど書籍のネタバレになってしまうので控える)
本書の全体像
この書籍は、一貫して
「WebブラウザはどのようにしてWebリソース間を適切に隔離(isolation)するか」
について書かれている。
具体的には、
- リソース間の論理的な隔離をどう達成するか
- リソース間のプロセスレベルの隔離をどう達成するか
- Cookieをどうセキュアに取り扱うか
- 出入りするリソースの信頼性をどう確保するか
の4つの問題に焦点をあて、第2章〜第5章まで各章ごとにそれぞれのトピックを掘り下げている。
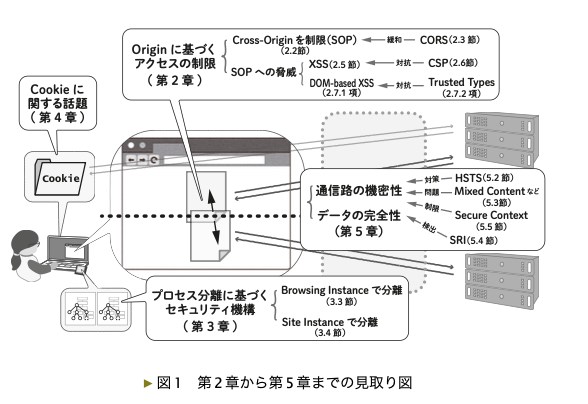
なぜ、このような観点を気にする必要があるのか?
1, 2:リソース間の論理的な|プロセスレベルの隔離
- WebブラウザはさまざまなWebアプリケーションが同時に動作するプラットフォーム
- 悪意のあるWebページを開いたことで、
- 同時に開いている別タブの情報が読み出せたら?
- Webブラウザに保存されているすべての情報(localStorageなど)にアクセスできたら?
- →ユーザーが受ける被害は甚大
- そのため、Webブラウザは、自身が取り扱うさまざまなリソース間を適切に隔離する必要がある
- リソース間の隔離、と言ったときに、論理的な隔離とプロセスレベルの隔離に分類して考えることができる
- 論理的な隔離
- プロセスレベルの隔離
3: Cookieのセキュアな取り扱い
- リソース間の隔離だけではなく、リソースとWebブラウザ内のデータストレージとの隔離も考えなくてはいけない
- Cookieは、Webブラウザ中に保存されており、かつHTTPリクエストを通して外部に送信されるという特徴がある。そのため、リソースの論理的な隔離、プロセスレベルの隔離に関する議論をそのままCookieにも適用するのは心もとない
4: 出入りするリソースの信頼性
- ブラウザ内でリソースを隔離できていたとしても、リソースがブラウザに届く前に改ざんしたり盗聴したりできてしまっては意味がない
- そのため、出入りするリソースの信頼性をどう確保するかにも関心がむけられるべき
各章ごとに学ぶキーワード
- 2章(Webリソースの論理的な隔離)
- OriginとSame-Origin Policy(SOP)
- CORS
- CSP(Content Security Policy)
- (おまけ程度に)Trusted Types
- 3章(Web ブラウザのプロセス分離によるセキュリティ)
- ブラウザのIsolation Model
- Site Isolation
- CORB、CORP、COEP、COOP(ぐへえ)
- 4章(Cookie)
- 5章 出入りするリソースの信頼性
感想
「本書の全体像」のところにも書いたけど、リソース間を適切に隔離するには?というテーマで一貫しており、かつ章ごとの内容は独立性が高いので気になるトピックだけかいつまんで読むこともできて良かった。
ただ、場所によっては説明が少々難しいと感じる部分があり、そのあたりはMDNなども適宜参照しながら知識を補っていった。
こちらの本も並行して読むとよかったかもしれない。

Same-Origin PolicyだったりCORS、CSRF、CSPのような略語表記の「なんか聞いたことあるけど人に説明できない」系の用語について、なぜそれが必要か?を理解しながら知識を整理できた。数ヶ月後に説明できるかは自信ないが、最後にちゃんとまとめたのでそれが活きると思いたい。
輪読会をやって良かったこと
まず何よりも、誰かと一緒にやることで最後までくじけずにやりきることができたので、同僚氏が誘いに乗っかってくれたのはほんとにありがたかった。わからないところも「うーんわからん!こういうことでは?」って言いながら前に進められたのは良かった。
あとは、CSPなどは特に業務ではあまり意識する機会がなかったせいか、みんな本当に使ってるの?とかイメージしきれない部分があったのだが、そういうときに実世界のユースケースをググってみたり実際のサービスでのリクエストをDevToolで覗いてなるほど〜とかやれたのはワイワイ感あって楽しかった。
CSPの事例でいうとこのあたり。
- 3rd-party JavaScript のリスク対策に CSP(Content Security Policy)を活用する - Yahoo! JAPAN Tech Blog
- Zenn に Content Security Policy を段階的に導入した話
- これはNext.jsでのサンプルがめちゃ丁寧に書かれてる
- Content Security Policy Level 3におけるXSS対策 - pixiv inside
- CSP、慎重に設定しないとサイトぶっ壊れるので、実際にはブロックせずレポーティングだけやるみたいな設定あった気がする。jxckさんやってたような
- これだ→Content Security Policy(CSP) 対応と report-uri.io でのレポート収集 | blog.jxck.io
Content-Security-Policy-Report-Only: default-src 'self'; report-uri https://example.com/csp-reportですって