引き続き、「みんなのデータ構造」という本を読む。
みんなのデータ構造(紙書籍+電子書籍) – 技術書出版と販売のラムダノート

前回
今回は「P32. 2.3 ArrayQueue 配列を使ったキュー」。
続きを読む引き続き、「みんなのデータ構造」という本を読む。
みんなのデータ構造(紙書籍+電子書籍) – 技術書出版と販売のラムダノート
前回
今回は「P32. 2.3 ArrayQueue 配列を使ったキュー」。
続きを読む「みんなのデータ構造」という本を読み始めたので、その読書メモを。
今回は 2.1 節の「ArrayStack」というデータ構造について。
https://sites.google.com/view/open-data-structures-ja/home より引用。
Open Data Structures は Pat Morin 氏が執筆した、データ構造の入門書です。本プロジェクトでは、この本の和訳を作成し、PDF ファイルおよびそのソースコードを公開しています。
データ構造やアルゴリズムについて学びたいと思っていたので、この本で勉強することにした。
PDF版であれば日本語でもフリーで手に入るが、私はラムダノート社のサイトから紙書籍+電子書籍版を購入した。
みんなのデータ構造(紙書籍+電子書籍) – 技術書出版と販売のラムダノート
また、書籍内のサンプルコードはC++で書かれているが、C++はわからないのでTypeScriptで写経することにした。
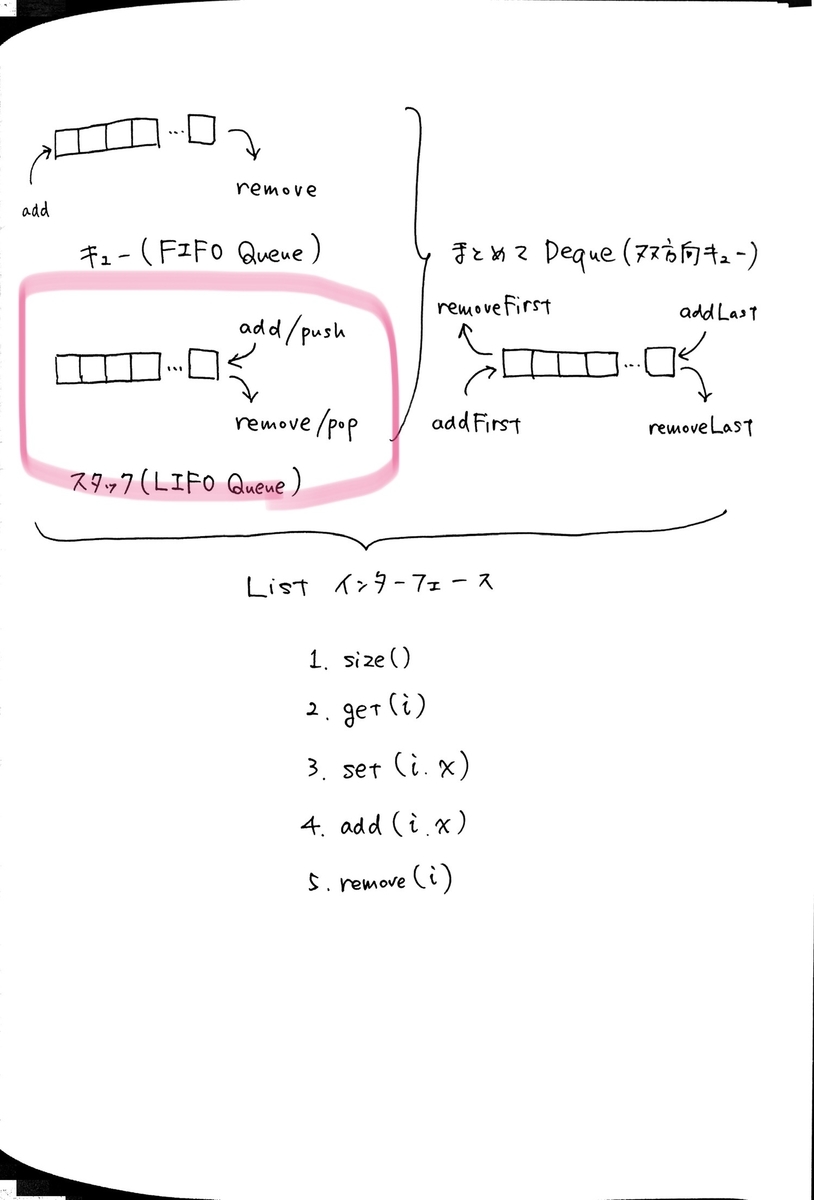
size(): リストの長さ n を返すget(i): set(i, x): add(i, x): remove(i): get(i) および set(i, x) の実行時間は O(1)add(i, x) および remove(i) の実行時間は
resize() を考慮しなければ O(n - i)resize() を考慮すると O(1 + n - i) ただしこれは償却実行時間
「償却実行時間」という言葉が出てくるが、これは「1.5 正しさ、時間計算量、空間計算量」の節に定義がある。
償却実行時間が
であるとは、典型的な操作にかかるコストが
個の操作にかかる実行時間を合計しても、
を超えないことを意味する。いくつかの操作には
要するに同じ操作を m 回やったときの実行時間から1回あたりの実行時間を考えるという話。
resize() の実行時間についてここがしばらくわからなかった。
空のArrayStackが作られたあと、
回の
add(i, x)およびremove(i)からなる操作の列が順に実行されるとき、resize()の実行時間はO(m)である。
書籍では
resize() が呼ばれるとき、その前の resize() から add/remove が実行された回数は n/2 -1 以上であるresize() の実行時間の合計は O(m) であるという2段階で説明しており、また 2 → 1 の順に証明している。
ここでは普通に1から書く。
resize() が呼ばれるとき、その前の resize() から add/remove が実行された回数は n/2 -1 以上であるresize()が呼ばれるのは、add(i, x) 内で呼ばれるケースと remove(i) 内で呼ばれるケースの2通りある。
add(i, x) 内で呼ばれる場合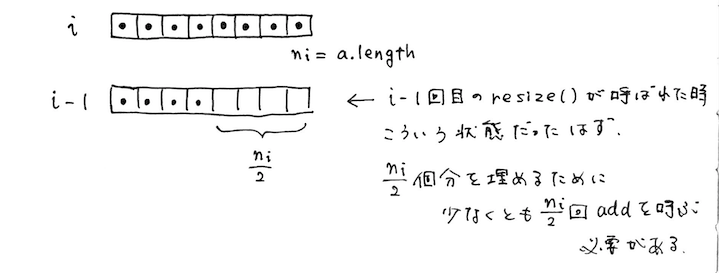
※書籍に倣って、「◯回めの resize() か」を表す◯に を使っているが、これは
add(i, x) の i とは無関係。ややこしい
この場合は i 回めの時点では配列 a は要素で満たされた状態、 i - 1 回めの時点では配列 a の長さは同じで、要素数は半分。
なので空いている a.length /2 = n_i / 2 分を埋めるのに、少なくとも n_i / 2 回の add() は実行されているはずである。
remove(i) 内で呼ばれる場合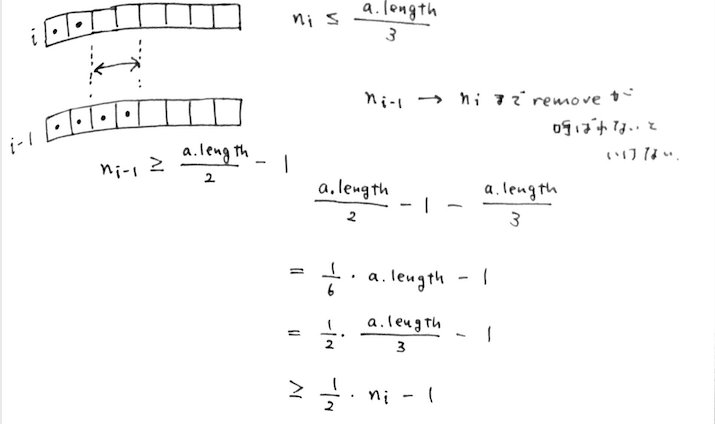
逆に remove(i) 内で呼ばれる場合、要素数 n_i が配列 a のサイズの 1/3 以下になる場合なので、 n_i <= a.length / 3。
1つ前の i - 1 回めの resize() が実行された直後の状況を考えると、このときは resize() によって配列のサイズの半分の要素数になっているはず。
n_(i-1) = a.length / 2 でもいいが、n = 0 && a.length = 1 という特殊ケースを考えると n_(i-1) >= a.length / 2 - 1 となる。
今度は要素数が n_(i-1) から n_i になるまで remove() が実行されているはずなので、差をとって↑のように式変形すると n_i / 2 - 1 以上であることが示せる。
resize() の実行時間の合計は O(m) である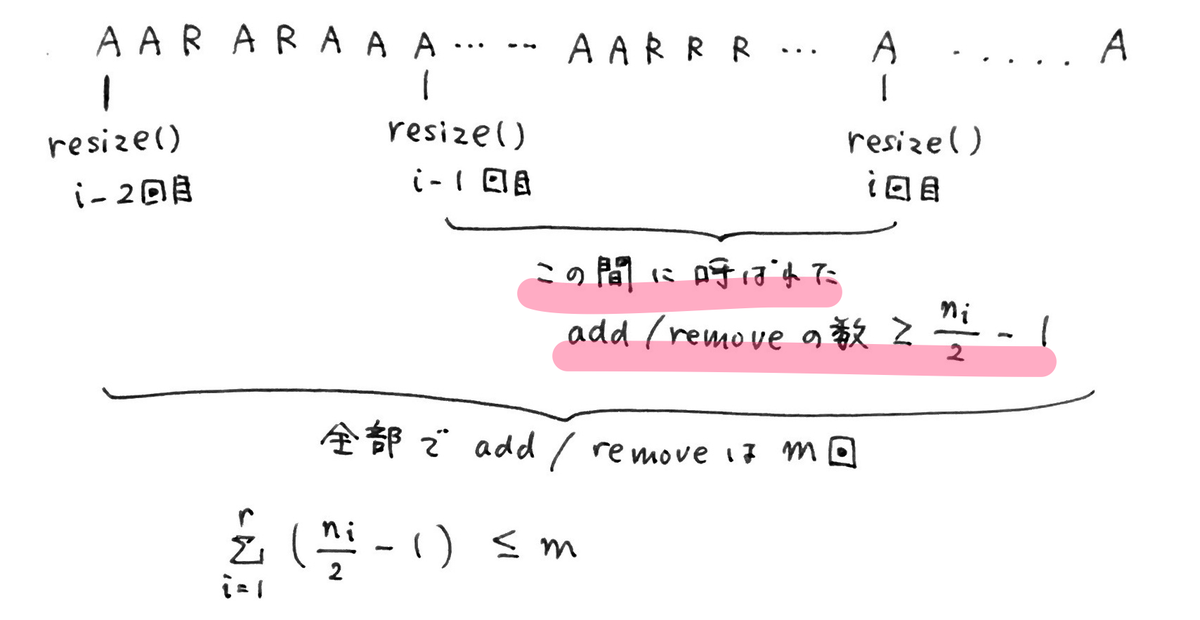
↑では、add(i, x)を A、 remove(i) を R と表現している。
いま、この AとRをランダムに実行した一連の操作があり、その操作の合計が m 回である。
またこの間に不定期に resize() が実行されており、合計で r 回実行された。
1でわかったのは色をつけた部分で、
「i - 1回めの resize() から i 回めの resize() の間に呼ばれた add/remove の数は >= n_i - 1 である」
ということ。
また、
(1回めのresize()から2回めのresize()までのadd/removeの数) + (2回めのresize()から2回めのresize()までのadd/removeの数) + ... + (i - 1 回めのresize()からi回めのresize()までのadd/removeの数) + ... + (r - 1 回めのresize()からr回めのresize()までのadd/removeの数) <= m
(r 回めの resize() の後にも何回か add/remove が呼ばれている可能性があるため)
で、かつ左辺のそれぞれの項は n_i /2 - 1 よりも大きいと言っているんだから、結局
が示せたことになる。
初ふりかえりです。
現職のサイボウズに入社したのが2018年12月なので、ほぼほぼサイボウズでの最初の1年という感じだった。
ブログは22件。
https://dackdive.hateblo.jp/archive/2019
登壇は(わずか)3件。
昨年はきちんと目標を立てていなかったが、なんとなく頭の中にあった「チャレンジしたいこと」が実際どうだったか。
現在、複業で react-lightning-design-system というReact製UIライブラリのTypeScript移行のお手伝いをさせてもらっており、その結果TypeScriptのお作法だったりESLint, Prettier, Jestなど周辺パッケージとの併用方法を学ぶことができた。
この記事は比較的多くの反応があったのでうれしい。
サイボウズは多くのチームでモブプログラミングという開発スタイルを採用している。
自分は現在kintoneというプロダクトチームと フロントエンドエキスパートチーム というチームを兼務しているが、kintoneチームに関しては100%モブプロ、フロントエンドエキスパートチームは個人作業とモブプロを両方取り入れた開発を行っている。
前職でもペアプロ・モブプロを取り入れてみたいなーという思いがあったのだが、実際に業務で体験してみて良い面も悪い面も知ることができた、というのが率直な感想。
入社してすぐに 社外のモブプロ体験会に参加した のは非常に良い経験だったし、モブプロに対する悩みMAXだった夏頃は自分でMeetupを主催するなどした。
またこちらの本も読んだが、これからモブプロを始めようと思っている人には有用な本だと思う。
これまで、OSSにIssueやPRを出すというのは自分にとって非常にハードルが高かった。
ところが、今所属しているチームのメンバーは日常的にOSSにIssue・PRを出しており、その影響から自分も一歩足を踏み出すことができた。
といってもバグ報告やドキュメントなどの簡単なtypo修正だけです。こういうの。
これもチームメンバーに刺激を受けて。
今までも読んでいたが、より日常的に読むようになった。
ブラウザのアップデート情報やカンファレンス動画を観るというのは、1年前はやっていなかったと思う。
個人的なおすすめは、Mozillaが昨年ぐらいから始めたこのYouTubeチャンネル。
トピックがCSSやアクセシビリティというのはあるが、尺としても10分前後のものが多く英語学習も兼ねて観るのに丁度いい。
転職して界隈を離れてしまったが、1年を通してSalesforceウォッチャーとしての活動は継続することができた。
さすがにリリースノートは読まないが、twitterから面白そうなアップデートを見たり、Dreamforceの発表内容を軽くチェックしたり、Meetupに顔を出すなどした。
Salesforceの動向をキャッチアップしている理由として「業務に無関係ではないこと」「今のところ開発者としての希少性を高められるのがSalesforceぐらいなこと」「キャッチアップをやめるとこれまでの経験が無になるという恐怖感」などいろいろあるが、今のところ無理なく続けられているので今年も継続したい。
これは転職して強く実感したことだが、ありがたいことに今同じチームにフロントエンドつよつよエンジニアしかいないので、今まで以上に自分の技術力の無さを思い知らされる。
どこかの領域では負けている、ではなく、知識・アウトプット力などさまざまな面で完全に劣っていると感じることが多々あり、恵まれた環境に感謝しつつこのままじゃやばいという危機感がある。
どこかの分野ではチームに貢献できるような強みを作りたい。今自分が興味あるのは
の3点だろうか。
昨年はいろんなことにチャレンジできて良かったと思う反面、腰を据えてやると決めたことが継続できなかったり、他の面白そうな話題に目移りしてしまうといったことが多々あったように思う。
これは昨年に限らず自分の弱みというか性格として認識しておかなければいけない。
この問題に対するTryとしては、継続できていることをちゃんと記録して可視化することだと思う。
GitHubみたく草が生えればもうちょっとモチベーションが続く気がする。Studyplusってそんな感じのアプリでしたっけ。
コンピュータサイエンス系の本については、気になっているのはこちらの本。
このブログを読んで↓
メモ。
Microsoftのこちらのブログを読んで。
In most cases, existing extensions built for Chromium will work without any modifications in the new Microsoft Edge
というのを見て、半信半疑で試してみた。
実際やってみると、必要な作業としてはMicrosoft Edge Addon Store に公開する作業だけで、ほんとに既存のChrome拡張のソースコードをそのまま使うことができた。
chrome.tabs や chrome.storage などのAPIがEdgeでもそのまま動く。
なお、記事執筆時点で新版 Microsoft Edge および Addon Store はベータ版という位置付け。
ベータ版 Edge はここからダウンロードできる→https://www.microsoftedgeinsider.com/ja-jp/download/
こちらが以前作ったChrome拡張:
同じものを今回 store に公開したもの:
https://microsoftedge.microsoft.com/addons/detail/cepmaeppcipafbfjonahpohfmolliblp

(なぜかアイコンの背景が青い)
Partner Center Developer Dashboard にアクセスするとアカウント登録を求められる。
GitHub アカウントでも登録できる。

もろもろ必要事項を入力する。
「Create new extension」からパッケージ(.zip)をアップロードし、Chrome ウェブストアのように必要事項を記入していく。
記載する内容はだいたいこんな感じ。
Chrome拡張として公開済みの場合、Edge用に新たに必要になるのはおそらく以下の2つの画像だけで済むはず。

後者については、今のところstoreのどこにも表示されないので謎。
以下、作りながら調べたこととかハマったこと。
ここの項目は、storeで公開したときに拡張名のすぐ下に表示される。

そのため、(Company Name)とあるが Account type が Individual であれば自身の名前やニックネームを付けた方が良い。
また、フォームにも書いてあるが、この項目を更新した際はそのままだとstoreには反映されず、拡張側の再Publishも必要。無意味にバージョンを上げる羽目になる。
初回だけでなく、パッケージのアップデート時も同じぐらいの日数を要した。
https://docs.microsoft.com/en-us/microsoft-edge/extensions-chromium/
このページから始まる、 Extensions(Chromium) というセクションにまとまっているよう。
Port Chrome Extension To Microsoft (Chromium)Edge - Microsoft Edge Development | Microsoft Docs
によると、
The Extension APIs and manifest keys supported by Chrome are code-compatible with Microsoft Edge. However, Microsoft Edge does not support the following Extension APIs:
chrome.gcmchrome.identity.getAccountschrome.identity.getAuthTokenchrome.identity.getProfileUserInfochrome.instanceID
Salesforce Platform Advent Calendar 2019 11日目の記事です。
遅れに遅れてすみません。OB枠*1からの参加です。
どなたかCustomer360について教えてください
— Shingo Yamazaki (@zaki___yama) 2019年11月27日
界隈を離れて1年経ちますが、なんだかんだSalesforceウォッチャーを続けています。
今年のDreamforceもDev向けの内容ぐらいは追っておこう...と思ってKeynote観ました(まとめ)。
そんな中で、いろんなKeynoteやリリース記事でCustomer 360という言葉を目にするものの、何を指してるのかあまりピンときてなかったのでここらで一度情報を整理しとこうという趣旨の記事になります。
間違ってたらご指摘ください。
※なお、Twitter上や先日の Tokyo Dreamforce Global Gatherings でも何人かからこのあたりの情報を教えていただきました。ありがとうございます
Customer 360という言葉自体が登場したのは、昨年のDreamforce 2018です。

動画(42:31あたり):Dreamforce: A Celebration of Trailblazers - YouTube
そして、おそらく同じタイミングでの記事がこちら。
ざっくりと、Sales Cloud、Service Cloudなどのデータと、Marketing CloudやCommerce CloudなどのB2C向けCloudで扱うデータにつながりがなかったのを連携できるようにします、ということのようですね。
また、GAが翌年の2019年であることも明記されています。
というわけで、昨年時点ではコンセプトレベルの紹介だったものを1年かけてエンハンスし、今年のDreamforceに持ってきたということかな。
日本でDreamforceの発表をウォッチしていて、気になったのはCustomer 360 Truthという新しいキーワードが登場していたことです。
後からKeynoteも探してみましたが、たしかにOpening Keynoteでも登場しています。

動画(1:17:46あたり) Dreamforce Opening Keynote: Trailblazers, Together - YouTube
マーク・ベニオフ曰く "new version of customer 360" だそう。
↑の記事を読む限り、Customer 360 Truthは具体的には
というサービスから構成されるもののようです。
https://www.salesforce.com/products/platform/features/customer-360-truth/
というプロダクトページを見てもそのように読み取れますね。
サービス間をつなぐためのおそらくキモとなる機能です。
こちらの紹介動画がわかりやすいです。
Salesforceの各Cloudや外部のデータシステムを連携し、顧客ごとにグローバルなIDで管理できるようになる、という機能ですね。
また、実際にデータソースを先に挙げたOpening Keynoteでもベニオフの発表の後にデモがあって、そこでもData Managerによって各Cloudをつなげる様子が見れます。
Trailheadモジュールも登場しています。
https://trailhead.salesforce.com/ja/content/learn/modules/customer-360-data-manager
気になるんだけど、Developer Editionで使えるものなんですかね?
Customer 360 Truthを構成するもう1つの機能ですが、こちらについては情報がほとんど見つかりませんでした。
Marketing Keynote: The New Decade of Data, Trust and Engagement - YouTube

マーケティング系のCloudでもデータ統合が進むのかな...という雰囲気ですが
そもそも日頃からこっちのサービスは情報追ってないんでよくわかりません。
また、GAが2020年ということなので、こちらはまだコンセプトレベルなんでしょう。
これは単にPlatformの呼び名が変わっただけと考えていいと思います。(M年ぶりN度目)
Keynoteのタイトルでも積極的に使われていますね。
別の話として、Platform Keynoteでは "Developer 360" というワードも登場しています。
動画 13:10


 こちらもまだほとんど情報が出ておらず、Keynoteで5分ほどデモで紹介されたのみです。
こちらもまだほとんど情報が出ておらず、Keynoteで5分ほどデモで紹介されたのみです。
観たところ
が特徴かな。
スピーカーは "one developer 360 for all of you to work together seamlessly as teams" と表現していました。
なんか頑張って調べたわりに完全に理解したとは言えない状況ですが、とりあえずData Managerだけがまともな「機能」としてリリースされたことはなんとなくわかりました。
いまCustomer 360とは何を指すのか?と聞かれると返答に困りますが、Customer 360 Platform 上にあるアプリケーション群っていうことなのかな。
*1:そんなものはない
この記事は kintone Advent Calendar 2019 6日目の記事です。
kintone のアドベントカレンダーは初参加です、よろしくお願いします。
kintone にはさまざまなAPIがありますが、その中でもちょっと特殊なのがAPIのスキーマ情報を取得するためのAPIです。
https://developer.cybozu.io/hc/ja/articles/201941924
これは、各APIのリクエスト・レスポンスがどういったパラメータで構成されているかを JSON Schema というフォーマットで返してくれるAPIです。
このリクエスト・レスポンスのデータ構造の情報を応用するといろんなツールに使えそうだと思い、今回はここからOpenAPI(旧Swagger)という規格のファイルを生成することで、REST APIドキュメントをいい感じに作成できないかな〜というのを試してみた話です。
JSON Schema とは、ざっくりいうとJSONのデータ構造をJSONで定義するための言語です。
たとえば、firstName, lastName, age というプロパティを持つ Person というJSONデータをJSON Schemaで表現すると以下のようになります。
{ "$id": "https://example.com/person.schema.json", "$schema": "http://json-schema.org/draft-07/schema#", "title": "Person", "type": "object", "properties": { "firstName": { "type": "string", "description": "The person's first name." }, "lastName": { "type": "string", "description": "The person's last name." }, "age": { "description": "Age in years which must be equal to or greater than zero.", "type": "integer", "minimum": 0 } } }
(https://json-schema.org/learn/miscellaneous-examples.html より引用)
一方のOpenAPIですが、こちらはREST APIの仕様を記述するためのフォーマットです。
Swagger という言葉をご存知の方は多いかもしれません。2015年にOpenAPI Initiativeという団体が発足したのに伴い、Swaggerは現在OpenAPIに名前が変わっているようです。
OpenAPIやSwaggerでREST APIの仕様を記述するメリットとして、その仕様を利用した便利なツールが充実していることが挙げられます。
今回使用するAPIドキュメント生成のためのツールもその1つです。
Swagger ◯◯と名のつくツール群については、以下の記事がわかりやすいです。
【連載】Swagger入門 - 初めてのAPI仕様管理講座 [1] Swaggerとは|開発ソフトウェア|IT製品の事例・解説記事
また、OpenAPIがどのようなフォーマットなのか、またそこからどのようなAPIドキュメントができるのかについては、Swagger Editorというオンラインエディタのデモサイト https://editor.swagger.io/ を見てみるのが良いかと思います。

以下、記事中のコードはすべてJavaScriptです。(↑のリポジトリではTypeScriptで書いています)
はじめに、APIのスキーマ情報を取得するAPIを実行し、結果をJSONで保存します。
流れとしては
/k/v1/apis.json) を叩き、全APIのスキーマ情報取得用のlinkを得る/k/v1/apis/*.json) を順番に実行し、各APIのスキーマ情報を得るという2ステップです。
import fetch from "node-fetch"; import fs from "fs"; import path from "path"; import prettier from "prettier"; const subdomain = process.env.KINTONE_SUBDOMAIN; export async function fetchKintoneAPISchemas() { const baseUrl = `https://${subdomain}.cybozu.com/k/v1`; // TODO: fetch all of kintone REST apis // const resp = await fetch(`${baseUrl}/apis.json`); // const apis: Apis = (await resp.json()).apis; // const fetchSchemasPromises = Object.values(apis).map(async api => { // const resp: any = await fetch(`${baseUrl}/${api.link}`); // return resp.json(); // }); // // const schemas = await Promise.all(fetchSchemasPromises); const schemas = [await (await fetch(`${baseUrl}/apis/app/acl/get.json`)).json()]; // (*) fs.writeFileSync( path.resolve(__dirname, "generated", "kintone-api-schemas.json"), prettier.format(JSON.stringify(schemas), { parser: "json" }) ); }
ただし、今回はとりあえず適当なAPI1つを例にうまくいくか試したかったので、アプリのアクセス権の取得API (/k/v1/app/acl.json)だけにしています。
全APIのスキーマ情報を取得したい場合は、(*) 行のかわりにコメントアウトしている部分を使うとうまくいきます。
生成した generated/kintone-api-schemas.json はこんな中身になっています。
[ { "id": "app/acl/get", "baseUrl": "https://zaki-yama.cybozu.com/k/v1/", "path": "app/acl.json", "httpMethod": "GET", "request": { "properties": { "app": { "format": "long", "type": "string" } }, "required": ["app"], "type": "object" }, "response": { "properties": { "rights": { "items": { "$ref": "Right" }, "type": "array" }, "revision": { "format": "long", "type": "string" } }, "type": "object" }, "schemas": { "Right": { "properties": { "recordImportable": { "type": "boolean" }, "appEditable": { "type": "boolean" }, "recordExportable": { "type": "boolean" }, "recordAddable": { "type": "boolean" }, "recordViewable": { "type": "boolean" }, "recordEditable": { "type": "boolean" }, "includeSubs": { "type": "boolean" }, "recordDeletable": { "type": "boolean" }, "entity": { "properties": { "code": { "type": "string" }, "type": { "enum": ["USER", "ORGANIZATION", "GROUP", "CREATOR"], "type": "string" } }, "type": "object" } }, "type": "object" } } } ]
続いて、先ほど保存したJSONファイルからOpenAPI Specificationという仕様に準拠したファイル(以下、OpenAPI Specファイルと呼びます)に変換します。
OpenAPIのドキュメントは、以下のようなフォーマットで記述します。
(YAMLでもJSONでもOKですが、読みやすさからYAMLで記述しています)
openapi: 3.0.1 info: description: Kintone REST API version: 1.0.0 title: Kintone REST API paths: /app/acl.json: get: parameters: - in: query name: app schema: type: string required: true responses: '200': description: OK content: application/json: schema: properties: rights: items: $ref: '#/components/schemas/Right' type: array revision: format: long type: string type: object components: schemas: Right: properties: recordImportable: type: boolean appEditable: type: boolean recordExportable: type: boolean ...(略)...
paths の下に各APIエンドポイントのパスを書き、リクエストを parameters に、レスポンスを responses に記述します。
一方、kintoneのAPIスキーマ情報のレスポンスとしては、request, responseにそれぞれリクエスト、レスポンスのパラメータ情報が含まれているので、これらをうまくマッピングしてあげれば良さそうです。
import fs from "fs"; import path from "path"; import yaml from "js-yaml"; import { convertRequestToParameters } from "./request-converter"; export function generateOpenAPISchema() { const kintoneAPISchemas = JSON.parse( fs.readFileSync( path.resolve(__dirname, "generated", "kintone-api-schemas.json"), "utf8" ), (key, value) => { if (key === "$ref") { return `#/components/schemas/${value}`; } return value; } ); const json = { openapi: "3.0.1", info: { description: "Kintone REST API", version: "1.0.0", title: "Kintone REST API" } }; const paths = generatePaths(kintoneAPISchemas); const components = generateComponents(kintoneAPISchemas); json.paths = paths; json.components = components; fs.writeFileSync( path.resolve(__dirname, "generated", "openapi.yaml"), yaml.safeDump(json) ); } function generatePaths(kintoneAPISchemas) { const paths = {}; kintoneAPISchemas.forEach(schema => { const key = `/${schema.path}`; paths[key] = { [schema.httpMethod.toLowerCase()]: { parameters: convertRequestToParameters(schema.request), responses: { "200": { description: "OK", content: { "application/json": { schema: schema.response } } } } } }; }); return paths; } function generateComponents(kintoneAPISchemas) { let schemas = {}; kintoneAPISchemas.forEach((schema) => { schemas = { ...schema.schemas, ...schemas }; }); return { schemas }; }
// request-converter.js export function convertRequestToParameters(request) { const parameters = []; Object.keys(request.properties).forEach(fieldCode => { const required = request.required.includes(fieldCode); parameters.push({ in: "query", name: fieldCode, schema: { type: request.properties[fieldCode].type }, required }); }); return parameters; }
https://github.com/zaki-yama/kintone-openapi-generator/blob/master/src/generate-openapi-schema.ts
スキーマ情報からOpenAPI Specのファイルが生成できたら、ここから周辺ツールを使ってREST APIドキュメントを生成します。
Swaggerのツール群でいうと Swagger UI がこれに該当します。
関連しそうなライブラリがいくつもあって迷ったんですが、今回は swagger-ui-express を使いました。
先ほど生成した OpenAPI Spec ファイルを読み込んで、以下のように渡してあげます。
// doc-server.js import fs from "fs"; import path from "path"; import jsyaml from "js-yaml"; import swaggerUi from "swagger-ui-express"; import express from "express"; const spec = fs.readFileSync( path.resolve(__dirname, "generated", "openapi.yaml"), "utf8" ); const doc = jsyaml.safeLoad(spec); const app = express(); app.use("/", swaggerUi.serve, swaggerUi.setup(doc)); app.listen(3000, () => { console.log("Listen on port 3000"); });
あとは、ターミナルで
$ node doc-server.js
でローカルサーバーを起動し、 http://localhost:3000 にアクセスすると...

無事APIドキュメントが表示できました。
なお余談ですが、VSCode というエディタを使っている場合は Swagger Viewer というextensionを入れると、エディタ上でこのようなAPIドキュメントを表示できます。
OpenAPI Specファイルを開いているときにコマンドパレットで
> Preview Swagger
というコマンドを実行してみてください。

ドキュメントをどこかのサイトにホスティングする必要がないのであれば、これでも十分ですね。
先ほど生成したAPIドキュメントには「Try it out」というボタンが表示されています。
ここから自社のkintone環境にリクエストを送り、実際のデータのレスポンスを確認できたら便利ですね。
というわけでトライしてみます。
実際のkintone環境にアクセスするには認証が必要ですが、調べてみるとOpenAPI Specファイルにいくつかの項目を追加すればいいことがわかります。
これによると、必要なのは以下の2点です。
servers > url にkintone環境のURLを指定する (例: https://hoge.cybozu.com)components > securitySchemes を指定する後者について、OpenAPIではベーシック認証やAPIキー(トークン)による認証、OAuth2といった認証認可のスキームをサポートしています。
一方kintone REST APIがサポートしている認証方式は kintone REST APIの共通仕様 > ユーザー認証 の項に記載があります。
残念ながらユーザー名・パスワードによる認証は一般的なベーシック認証とは異なるため、ここではAPIトークン認証を使います。
APIトークン認証はトークンを X-Cybozu-Authorization というヘッダーに乗せて送ります。これはOpenAPIでは以下のように書きます。
components: securitySchemes: ApiTokenAuth: type: apiKey in: header name: X-Cybozu-API-Token ... # 最後にこれも必要っぽい security: - ApiTokenAuth: []
servers > url と合わせて、ステップ2で作成したスクリプトに処理を追加しておきます。
詳しくはリポジトリの generate-openapi-schema.ts を参照ください。
さて、この状態で再度APIドキュメントを立ち上げると、期待通りAuthorizeというボタンが追加されています。
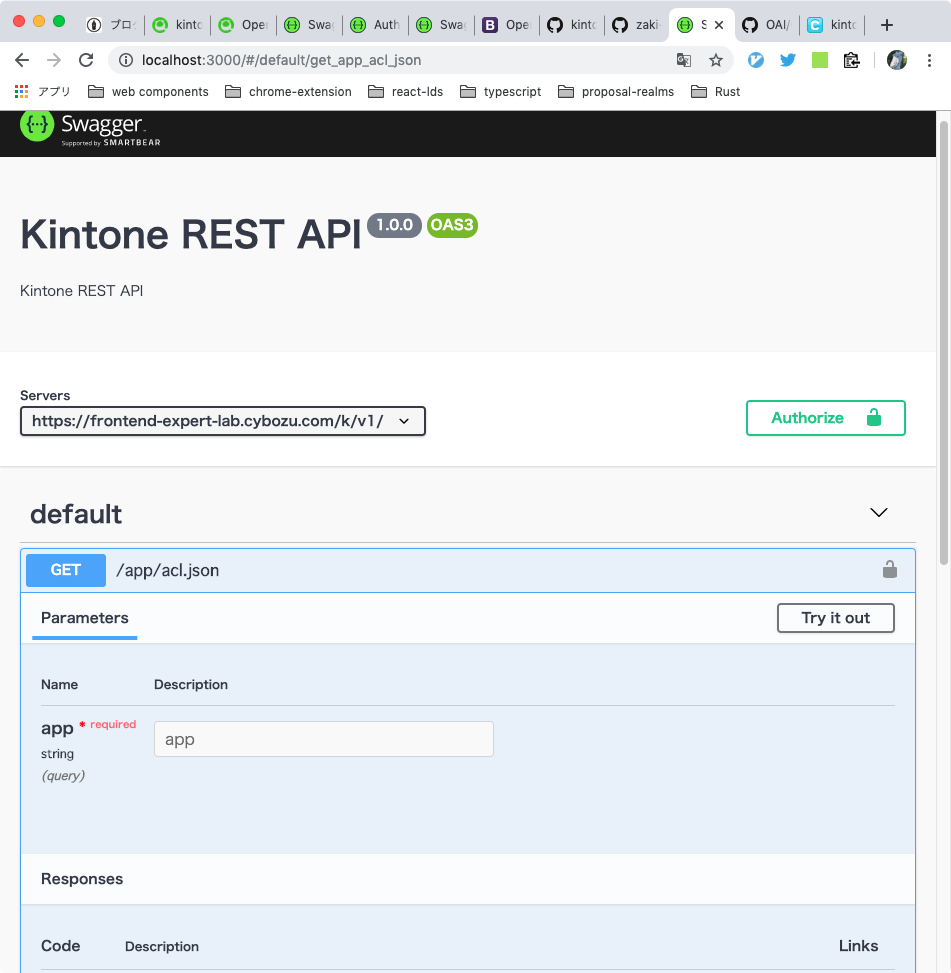
kintoneで発行したAPIトークンを入力してAPIを実行してみましたが、エラーになってしまいました。

localhostだからいけない(httpsならいける?)のか、それとも結局同一ドメインじゃないとうまくいかない...?
というのを調査しようと思いましたが、残念ながら時間切れです。
OpenAPI を利用したツールは今回紹介したAPIドキュメント生成以外にもさまざまなものがあります。
別の活用例として、たとえば prism というツールを使うと、モックサーバーを生成することもできます。
$ npm install @stoplight/prism-cli
でインストールし、
$ ./node_modules/.bin/prism mock <OpenAPI Specファイルのパス>
というコマンドを実行するだけです。
# モックサーバー起動 $ ./node_modules/.bin/prism mock <OpenAPI Specファイルのパス> [01:13:41] › [CLI] … awaiting Starting Prism… [01:13:41] › [HTTP SERVER] ℹ info Server listening at http://127.0.0.1:4010 [01:13:41] › [CLI] ℹ info GET http://127.0.0.1:4010/app/acl.json?app=magni [01:13:41] › [CLI] ▶ start Prism is listening on http://127.0.0.1:4010 # 別ウィンドウで $ curl "http://localhost:4010/app/acl.json?app=1" {"rights":[{"recordImportable":true,"appEditable":true,"recordExportable":true,"recordAddable":true,"recordViewable":true,"recordEditable":true,"includeSubs":true,"recordDeletable":true,"entity":{"code":"string","type":"USER"}}],"revision":"string"}%
ここまでやって、一通り完成したように見えましたが、このまま全APIのスキーマをOpenAPI Specファイルに変換しようとしたところ、盛大にエラーが出ます。

エラーメッセージを少し見た様子だと、OpenAPIとして期待している型が違う(integerを期待しているところが文字列)だったり、patternPropertiesなどOpenAPIがサポートしていないJSON Schemaのキーワードを使用しているのが問題のようです。
前者はまだいいとして、後者にちゃんと対応するのはなかなか大変そうですね。。。(そもそも回避できるのかもわかってない)
JSON SchemaもOpenAPIも今回初めてまともに使用したのでうまくいくか全くわかりませんでしたが、それっぽいものを作ることはできました。
とはいえ、TODOに書いたように完全なREST APIドキュメントを生成できるようにするのはだいぶハードルが高そうです。
また、調べていて苦労した点は、どのツールがデファクトスタンダードなのかあまりよくわからなかったというところです。
今回はGitHubのStar数やコミットの最終更新日時などを判断材料に選定しましたが、適切な選択になっていたかはわかりません。
また、そもそもツールを探すのも一苦労でした。
一応、今回の知見としてOpenAPI.Toolsというツール一覧サイトがあるようです。
OpenAPI関連でやりたいことがあれば、まずはこのサイトを見るのがいいのかなーと思いました。
このサイトの信頼性もよくわかりませんが。。。
ブログ
動画
ブログ記事を読みながら動画をとばしとばし観た感じです。
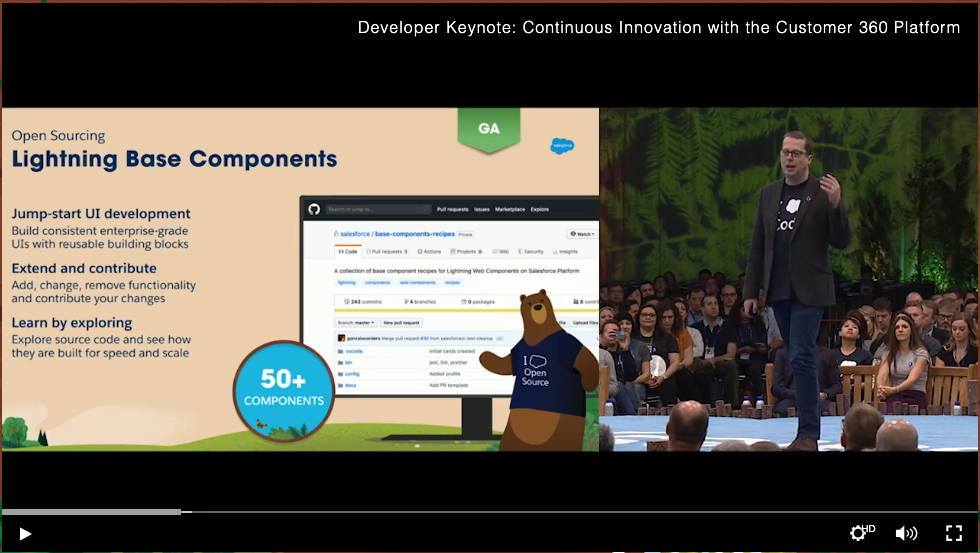
動画09:30あたり。
先日のLWCのオープンソース化に続き、Lightning Base Componentsという基本コンポーネント群もオープンソース化したそうです。
最初、リポジトリ名からBase Compoentsそのものでなくこれらを使ったサンプル集でしかないのかな、と思いましたが
このディレクトリ下がBase Componentsにあたりそうですね。
https://github.com/salesforce/base-components-recipes/tree/master/force-app/main/default/lwc
 動画10:15あたり。
動画10:15あたり。
かなりインパクトのある発表だったんじゃないでしょうか。
英語だけでなくほぼ同時に日本語でも紹介ブログが投稿されたあたり、本気度が伺えます。
ざっくり
ということは把握しましたが、まだブログもデモもちゃんと見れてないので別途詳細を書く。

動画24:45あたり。
利用可能なAPIが一箇所にまとまったサイトができた、かな。おそらくまだリリースはされてない。
この後のBlockchain関連のところ(33:00あたり)でデモされてます。

URLが https://**********.for.com/kjcapi/... となっているので、各Salesforce組織内に含まれるイメージ?
Select API Instanceというのはおそらくモックを叩くか実際の組織のデータを扱うかを選択できるってことで、これはAPIドキュメントとしてはかなり便利そう。

動画24:45ぐらい。
元々のVision & Languageに加えMulti-Language、OCR、Voiceなどの新機能がリリース。
前に書いたので割愛。


数分で構築が完了する新しいSandbox(速度以外は従来のFull Sandboxと何が違うの?)と、そのSandboxで使えるデータのマスク機能。
運用環境のデータでテストしたいけどセンシティブなデータはマスクしたい...!っていうの実際あるので便利。
マスク方法はフィールドごとに以下の3種類から選べる。
Blake → gB1ff95-$Kelsey → Amber
動画43:54あたりにデモあり。

Winter'20でGAになった機能らしいです。知らんかった。
イベントデータのほぼリアルタイムのストリーミングおよび保存 (正式リリース)
ヘルプもある:リアルタイムイベントモニタリング
リアルタイムイベントモニタリングを使用すると、次の点についてより貴重なインサイトを得ることができます。
- 誰がいつどのデータを表示したか
- どこでデータがアクセスされたか
- いつユーザが UI を使用してレコードを変更するか
- 誰がどこからログインしているか
- 組織の誰がプラットフォームの暗号化管理に関連するアクションを実行しているか
- どのシステム管理者が別のユーザとしてログインし、そのユーザとしてどのアクションを実行したか
- Lightning ページの読み込みにどのくらいの時間がかかるか
Transaction Security Policyについては動画47:45あたりにデモあり。

ユーザーがこのオブジェクトのレコードを閲覧しようとしたら、操作をブロックしつつ管理者に通知する、みたいなことがGUIでできるようになったのかな。

動画一番さいご。
"Lightning Web Runtime Beta"と"GitHub App Support Beta"が気になります。
前者はこないだLWCローカル開発機能を調べてたときに見つけた @webruntime/common とかだろうな。

