React 16 Beta がリリースされました。
Error Boundary という概念が導入されたそうなので公式ブログをざっくり読んでみます。
はじめに:React 15 までの問題
React 15 まではコンポーネントで発生したエラーをうまくハンドリングしたり、そこからリカバリするためのしくみが提供されてませんでした。
結果として
- コンポーネントのどこかで JavaScript エラーが発生する
- catch していない場合、知らないうちに React の内部状態(internal state)にも悪影響を及ぼす
- 結果として開発者コンソール上はぱっと見原因がよくわからないエラーが発生する
みたいなことが起きてました。
(参考)
TypeError: Cannot read property '_currentElement' of null · Issue #4026 · facebook/react
Error: performUpdateIfNecessary: Unexpected batch number ... · Issue #6895 · facebook/react
Cannot read property 'getHostNode' of null · Issue #8579 · facebook/react
Error Boundary の導入
デモ:https://codepen.io/gaearon/pen/wqvxGa
Error Boundary は 子コンポーネントツリーで発生したエラーをハンドリングする ための React コンポーネントです。
ブログに記載されているサンプルコードを見てみます。
class ErrorBoundary extends React.Component { constructor(props) { super(props); this.state = { hasError: false }; } componentDidCatch(error, info) { // Display fallback UI this.setState({ hasError: true }); // You can also log the error to an error reporting service logErrorToMyService(error, info); } render() { if (this.state.hasError) { // You can render any custom fallback UI return <h1>Something went wrong.</h1>; } return this.props.children; } }
注目すべきは componentDidCatch(error, info) という新しいライフサイクルメソッドで、これが実装されたコンポーネントのことを Error Boundary と呼ぶようです。
使うときは
<ErrorBoundary> <AddTodo /> <VisibleTodoList /> <FilterLinkList /> </ErrorBoundary>
のように、エラーをハンドリングしたいコンポーネントツリーをラップするようにして通常のコンポーネントと同じように記述します。
このようにすると、<ErrorBoundary> 以下のコンポーネントツリーで JavaScript エラーが発生したときに componentDidCatch() がエラーを捕捉してくれます。
(レンダリング時だけでなく、コンストラクタやライフサイクルメソッド内で発生したエラーも捕捉できます)
try/catch の catch 句と同じですね。
そのため、あるコンポーネントツリーでエラーが発生したときもクラッシュせず
ログを送信したり、エラーメッセージ用のコンポーネントに差し替えるといった対応が可能になります。
注意
Error Boundary が捕捉するのは 子コンポーネントツリー内で発生したエラーのみで、自コンポーネント内で発生したエラーは捕捉できません。
つまり Error Boundary コンポーネント内のライフサイクルメソッドや render() の書き方をミスってエラーが発生した場合、それは componentDidCatch() で捕捉できません。
componentDidCatch(error, info) の引数の中身
デモ を確認した限り、
- 第一引数の
errorは Error オブジェクト(messageとstackをプロパティとして持つ) - 第二引数の
infoはcomponentStackというプロパティを持つオブジェクト
のようです。
また componentStack には
in BuggyCounter (created by App) in ErrorBoundary (created by App) in div (created by App) in App
のような情報が入っています。Component Stack Trace と呼んでいるようです。(後述)
Error Boundary はコンポーネントツリーのどこに配置すべきか
Error Boundary は複数配置することも可能なので、ツリーのどこに Boundary を設けるかは要件次第です。
アプリケーションのルートに「不明なエラー(Something went wrong)」というメッセージを表示する Boundary を1個だけ置いてもいいですし、
画面の一部分が壊れても他の部分は利用可能な状態を維持したいのであれば、その境界ごとに複数の Boundary を用意する可能性も考えられます。
例として、Facebook Messenger はサイドバーや info panel、チャット部分などはそれぞれ Error Boundary でラップしてるそうです。
Uncaught Error 時の挙動の変更
個人的にこれが大きな仕様変更だなと思いました。
React 16 から、どの Error Boundary でも捕捉されないエラー(Uncaught Error)が発生した場合 コンポーネントツリー全体が unmount され、非表示になります。
先ほどのデモを fork して試してみます。
https://codepen.io/zaki-yama/pen/dzYWNM
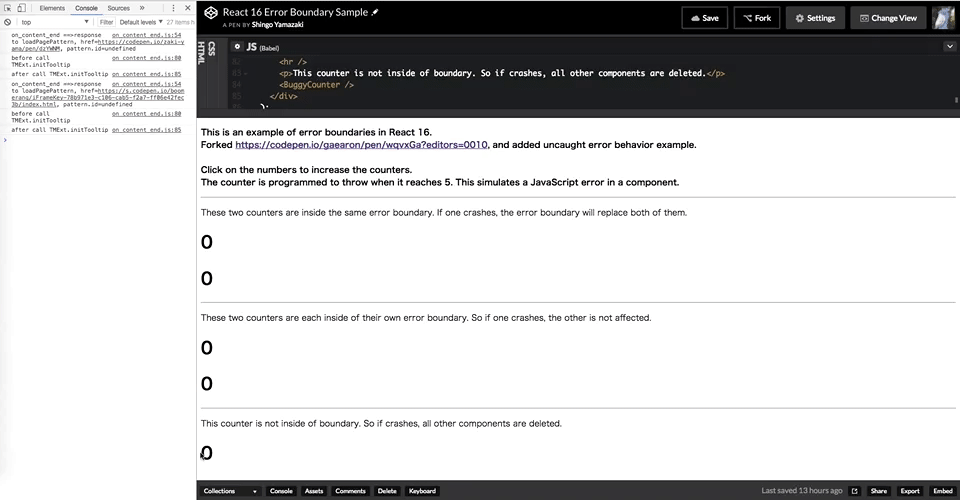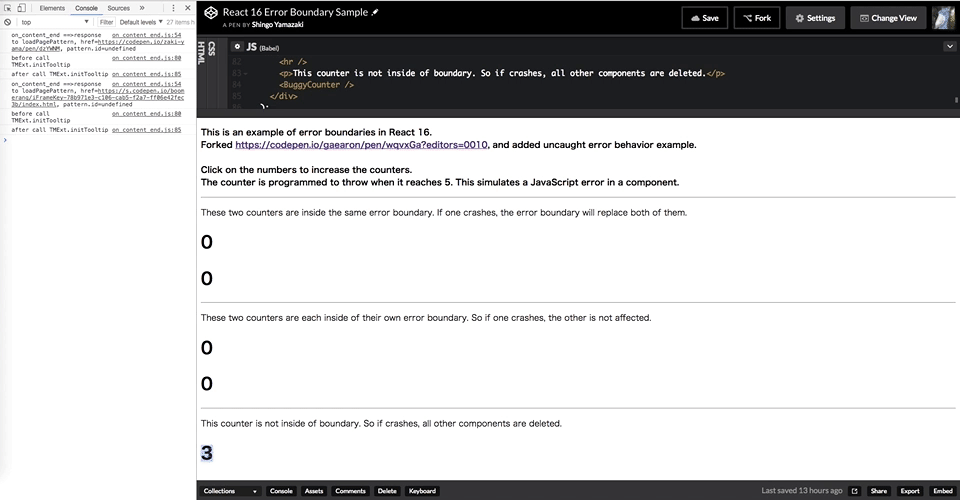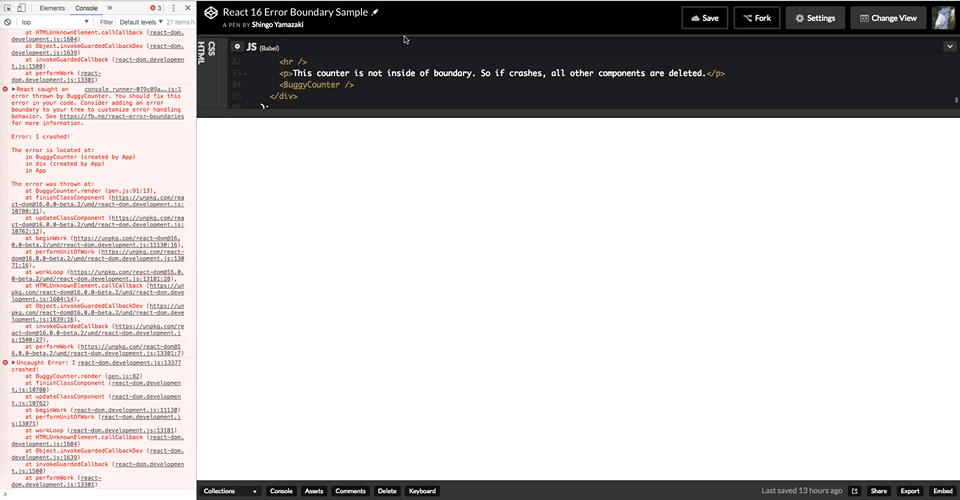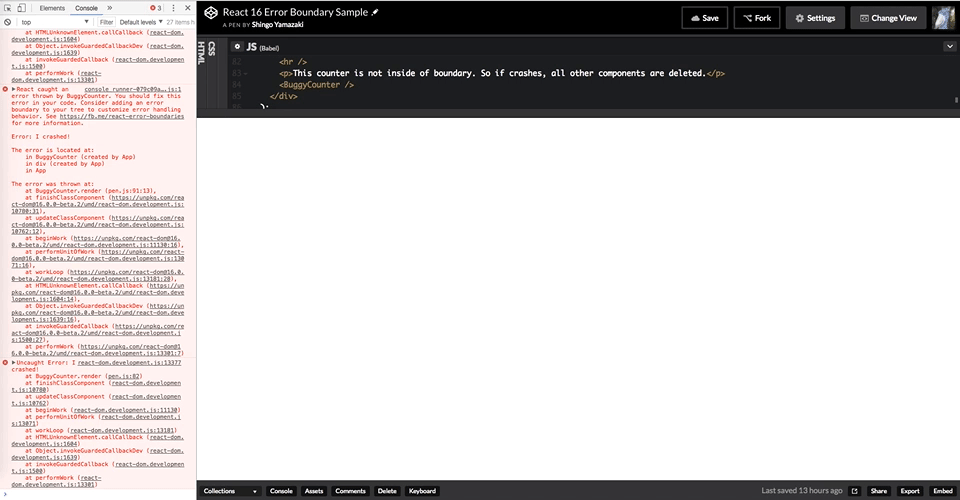
一番下に追加したカウンター(インクリメントして 5 になるとエラー)は Error Boundary でラップしていないのですが、ここで発生したエラーのせいで画面全体がクリアされているのがわかります。
React 15 のときの挙動と比較
https://codepen.io/zaki-yama/pen/RZWVpK
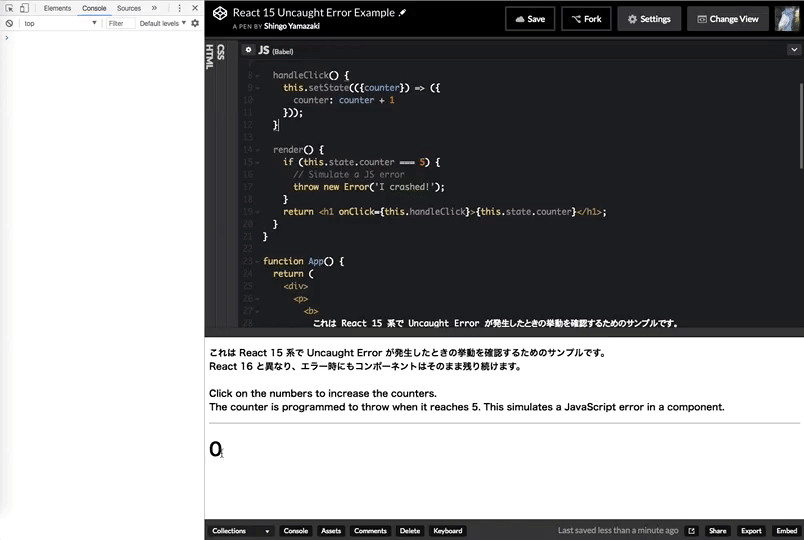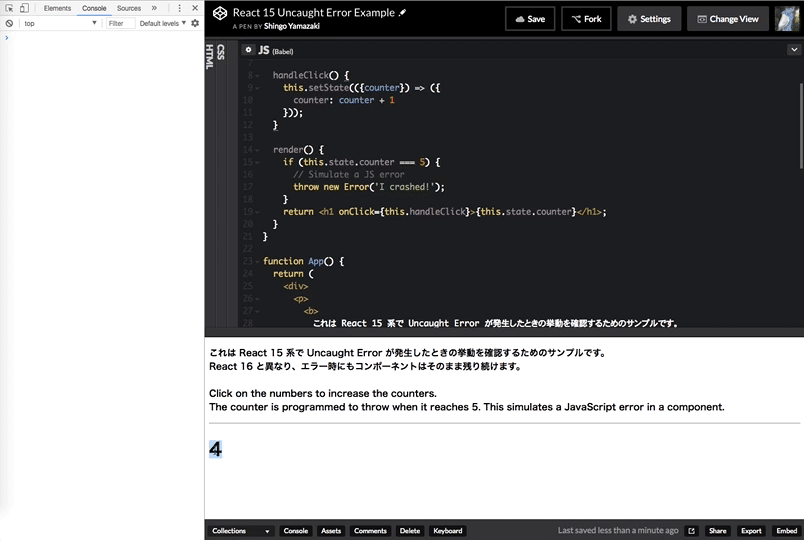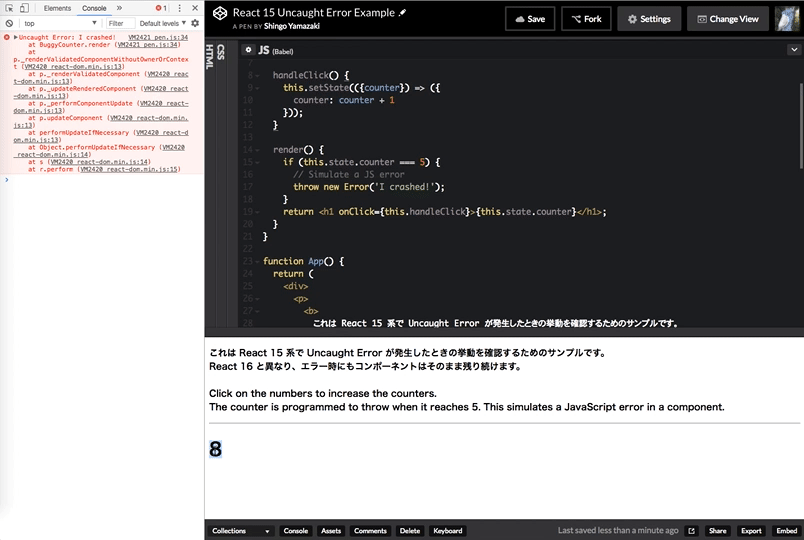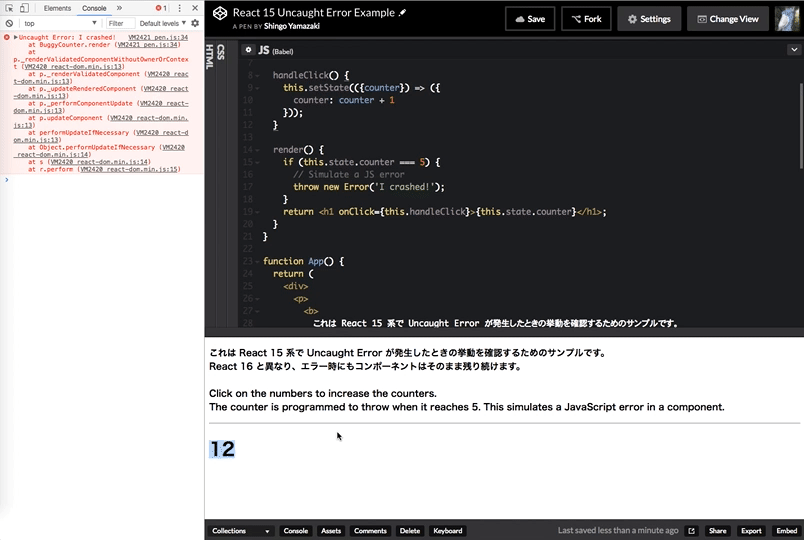
React 15 のときはコンソールでエラーが発生しているものの、画面自体はそのまま残っていることがわかります。
なぜこのような仕様に変更されたのか
全コンポーネントツリーが unmount されて画面全体が操作不能になることより、エラーによって UI や内部状態がおかしくなったことに気づかず中途半端に動作し続けることの方がまずい、との結論に達したようです。
たとえば、商品の支払い画面の UI で実際に表示されている金額と内部で保持している金額が乖離したまま決済を実行されるリスクがあるのは危険ですね。
Component Stack Traces
React 16 ではレンダリング中に発生したエラーは必ずコンソールに出力されます。(in development とあるので NODE_ENV === development の時のみ?)
ログにはエラーメッセージと JavaScript の stack trace に加え、コンポーネントの stack trace も出力されるようになります。
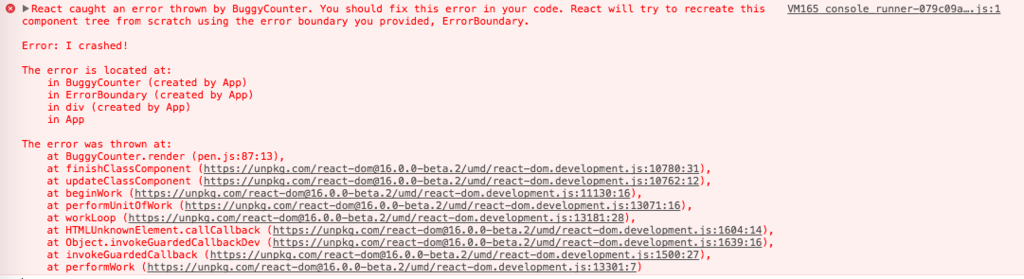
これにより、コンポーネントツリーのどのコンポーネントでエラーが発生したのか追いやすくなります。
さらにファイル名と行番号も出力する
component stack trace にファイル名と行番号を出力することもできます。create-react-app の場合はデフォルトで有効になっています。
creacte-react-app を使わない場合、babel-plugin-transform-react-jsx-source という Babel プラグインを追加する必要があります。
また追加した際は production build 時には無効化する必要があります。
感想
これまで、アプリで発生したエラーを React ではどのように処理すべきなのかがいまいちわかっていなかったんですが、Error Boundary の導入によって基本的な実装方法がわかりました。
エラー時に外部の error reporting サービスに送信したり、UI のパーツごとに境界を設けてあるパーツが壊れても他のパーツは機能するように、といった制御はかなりやりやすくなりましたね。
Uncaught Error 時の仕様変更については、予期せぬエラーで画面が真っ白になるという状況は避けたいので、アップデート前に最低限アプリのルートには Boundary を設けておいた方が良さそうです。
React 16 Beta を今すぐ試すには
React 16 beta · Issue #10294 · facebook/react
によると
# Yarn yarn add react@next react-dom@next # Npm npm install --save react@next react-dom@next
でインストールできるそうです。未確認。